



介绍
从这一章开始,我们开始学习进程。首先需要学习的是为单个进程提供新抽象:线程(thread)。比较经典的观点是一个程序只会有一个执行点(一个pc计数器,用来存放要执行的指令),如果是多线程(mulit-threaded)的程序会有多个执行点(多个pc计数器,每个都是单独的取指令和执行)。
从另一个角度来看,每个线程类似于独立的进程,只有一点区别:它们是共享地址空间,可以访问相同的数据。
因此单个线程的状态和进程状态非常类似。线程有一个程序寄存器(PC寄存器),记录程序从哪里获取指令,它还会有一组用于计算的其它通用寄存器。
如果两个线程运行在同一颗CPU上,当发生上下文切换(context switch)的时,线程之间的上下文切换和进程的切换也很类似。
对于进程切换,进程的状态会保存到进程控制块(Process Control Block, PCB)。
线程的话,它也有一个线程控制块(Threaded Control Block, TCB)来记录线程之间的状态。它和进程的区别是:地址空间是保持不变的(即不需要切换页表)。
进程和线程之间还有一个区别是栈。在单线程(single-threaded)进程中,只会有一个栈,一般位于地址空间的底部,如下图左侧所示

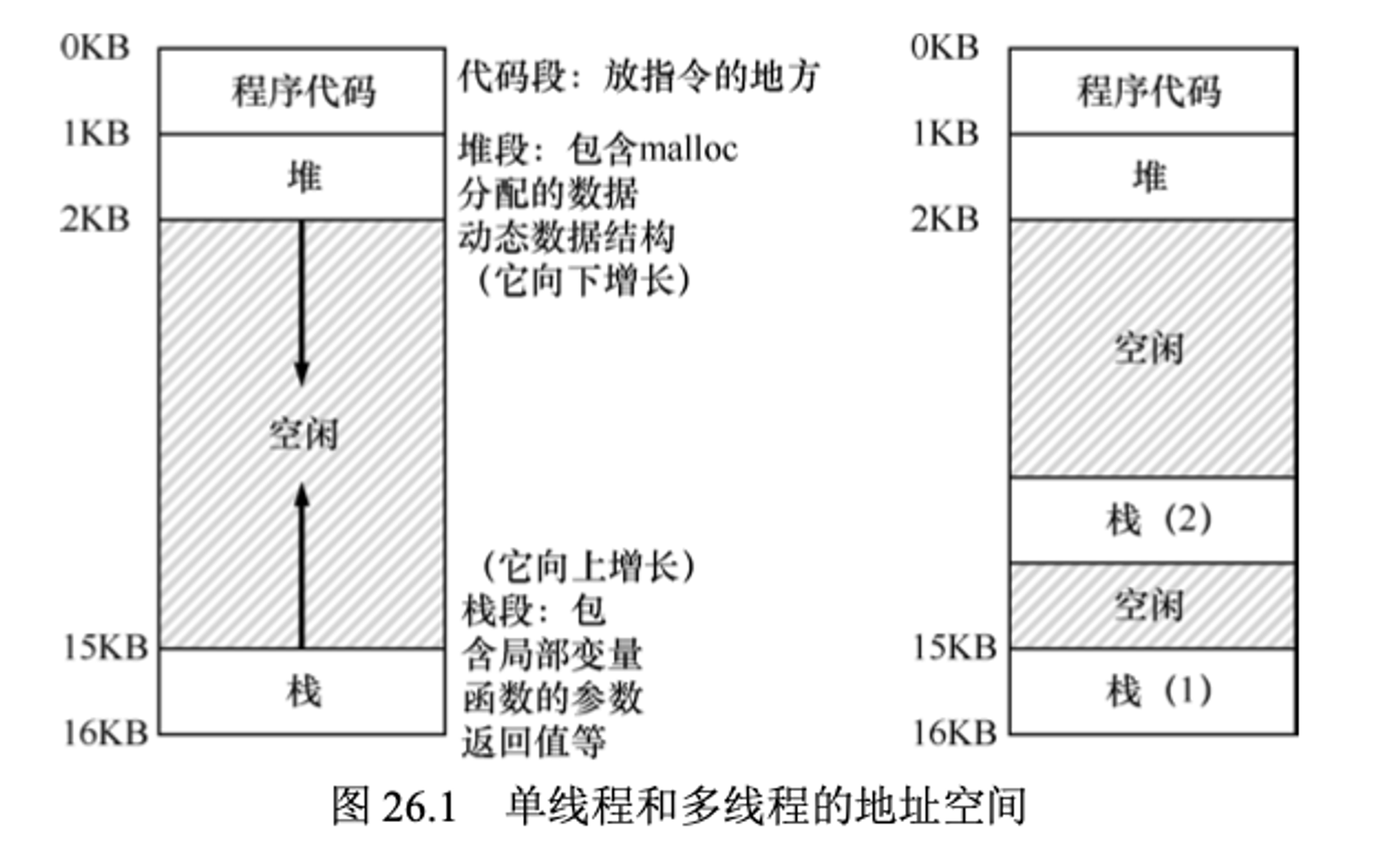
然而在多线程中,每个线程都是单独运行的,它们会调用各种例程来执行对应的工作。因此每个线程都会有自己独立的栈。假设一个多线程的进程,它有两个进程,在地址空间中就会有两个栈(如上图右侧所示)。
上图可以看到有两个栈横跨了进程的地址空间。因此,所有位于栈上的变量、参数、返回值和其它放在栈上的东西,将被放置在有时称为线程本地(thread-local)存储的地方,即相关线程的栈。
我们也发现了,多个栈也破坏了的地址空间的美感。以前堆和栈可以互不影响的增长,直到占满空间。多个栈的话就不会那么简单了。幸运的是,栈通常会很小(除非死循环或者不断递归)
进程创建
假设我们现在想要运行一个程序,这个程序创建了两个线程,每个线程做的事情都不一样,在我们的例子中,这俩进程分别打印“A”和”B“。
如下代码所示,主程序分别创建了两个线程,这俩个线程都执行了
mythread(),只是参数不一样(A和B)。这里需要注意,当线程一创建,可能会立即执行,也可能处于就绪态后等待执行(这取决于调度程序)。下面可以看到创建了两个线程(p1和p2),主程序调用
pthread_join()(这个函数会同步阻塞等待子线程运行完成)等待对应的线程完成。我们可以通过下图来看这个程序的执行顺序,向下方表示时间增加,每个列显示不同的线程(主线程、线程1或线程2)何时运行。
主程序 | 线程1 | 线程2 |
开始运行
打印 ”main: begin”
创建线程1
创建线程2
等待线程1 | ㅤ | ㅤ |
ㅤ | 运行
打印 ”A“
返回 | ㅤ |
等待线程2 | ㅤ | ㅤ |
ㅤ | ㅤ | 运行
打印 ”B“
返回 |
打印 ”main: end” | ㅤ | ㅤ |
这里需要注意,这个顺序并不是绝对的顺序。它可能顺序会有些不太一样,这取决于调度程序决定在某个时刻到底要运行哪个线程。例如,当一个进程创建完后可能会立即就进行执行,这样的话,顺序可能会如下图所示。
主程序 | 线程1 | 线程2 |
开始运行
打印 ”main: begin”
创建线程1 | ㅤ | ㅤ |
ㅤ | 运行
打印 ”A“
返回 | ㅤ |
创建线程2 | ㅤ | ㅤ |
ㅤ | ㅤ | 运行
打印 ”B“
返回 |
等待线程1
立即返回,线程1已完成
等待线程2
立即返回,线程2已完成
打印 ”main: end” | ㅤ | ㅤ |
还有一种可能,我们还可能会先看到进程B先执行完(复制上述代码运行多次可以看到),那么结果会如下图所示
主程序 | 线程1 | 线程2 |
开始运行
打印 ”main: begin”
创建线程1
创建线程2 | ㅤ | ㅤ |
ㅤ | ㅤ | 运行
打印 ”B“
返回 |
等待线程1 | ㅤ | ㅤ |
ㅤ | 运行
打印 ”A“
返回 | ㅤ |
等待线程2
立即返回,线程2已完成
打印 ”main: end” | ㅤ | ㅤ |
这里还有实际的运行结果
正如我们所看到的,线程创建有点类似函数调用。但是它不是执行完函数后立马返回给调用者,而是为即将执行的例程创建一个新的线程,它是独立于调用者运行的,它可能会在调用者返回之前运行,但也可能会晚很多。
这个例子已经可以体现,线程会让情况变得更复杂:因为已经很难说清楚具体哪个线程什么时候会运行了!在没有考虑并发的时候计算机很难理解了。更糟的是,当需要考虑并发情况时,事情会变得更加棘手。
为什么更糟糕:共享数据的竞态问题
考虑如下一个场景,两个线程都在操作同一个变量。将一个数加1000万次,我们预期的结果是20000000(即两个10000000相加),实际代码如下
我们来执行几次上述代码来看看结果
可以看到,每次的结果都不一样,而且都没有达到预期的结果
了解并使用工具
通过反汇编程序(disassembler)可以对可执行文件进行反汇编,它会返回组成程序的汇编指令。
objdump是一个常用的需要掌握工具之一,当然还有gdb这样的调试器,valgrind和purify这样的内存分析器,以及编译器自身也应该花很多时间去了解更多信息。工具用的越好,就可以建立更好的系统,我们可以通过运行如下命令来查看汇编代码。
prompt> objdump -d main核心问题:不可控的调度
为了理解上述情况为什么会发生,我们通过一段简短的汇编代码来更易理解,这个例子中,我们的核心操作就是将counter加1。那么对于
x86的机器来说,可能会生成如下汇编代码,这段代码从地址100位置起始(RISC指令集是可变指令,mov执行占5个字节,add只占3个字节)。这段代码会假设couter位于地址
0x8049a1c。第一条指令会先从这个地址中将值放到eax寄存器中。接着再将eax寄存器的值加1。最后将eax的值写回到地址0x8049a1c中。现在设想线程1开始执行,且counter的值目前是50,它将50加载到寄存器
eax中。接着再将其加1,目前线程1的eax寄存器值为51。就在此时,发生了时钟中断。操作系统将线程1的状态(程序计数器,寄存器,包括eax等)保存在了线程的PCB。紧接着,调度程序将线程2选中,它也从
0x8049a1c将counter的值加载到它的eax寄存器中(每个线程都有自己的专用寄存器),此时counter的值依旧是50,因为线程1还没来得及将值更新,就被打断了。接着它也将eax的值加1,此时线程2的eax值为51,最后它将eax寄存器的值设置到0x8049a1c中,也就意味着counter现在是51。随后,又发生了一次上下文切换,线程1恢复执行。线程1的
pc寄存器知道即将运行的指令是最后一条mov指令。回忆一下,线程1的eax之前还是51。因此counter又会被再次设置成51。简单地说,正确的结果应该是:counter被执行两次初始值是50,结果应该是52才对。
如下图是这段代码的执行顺序图

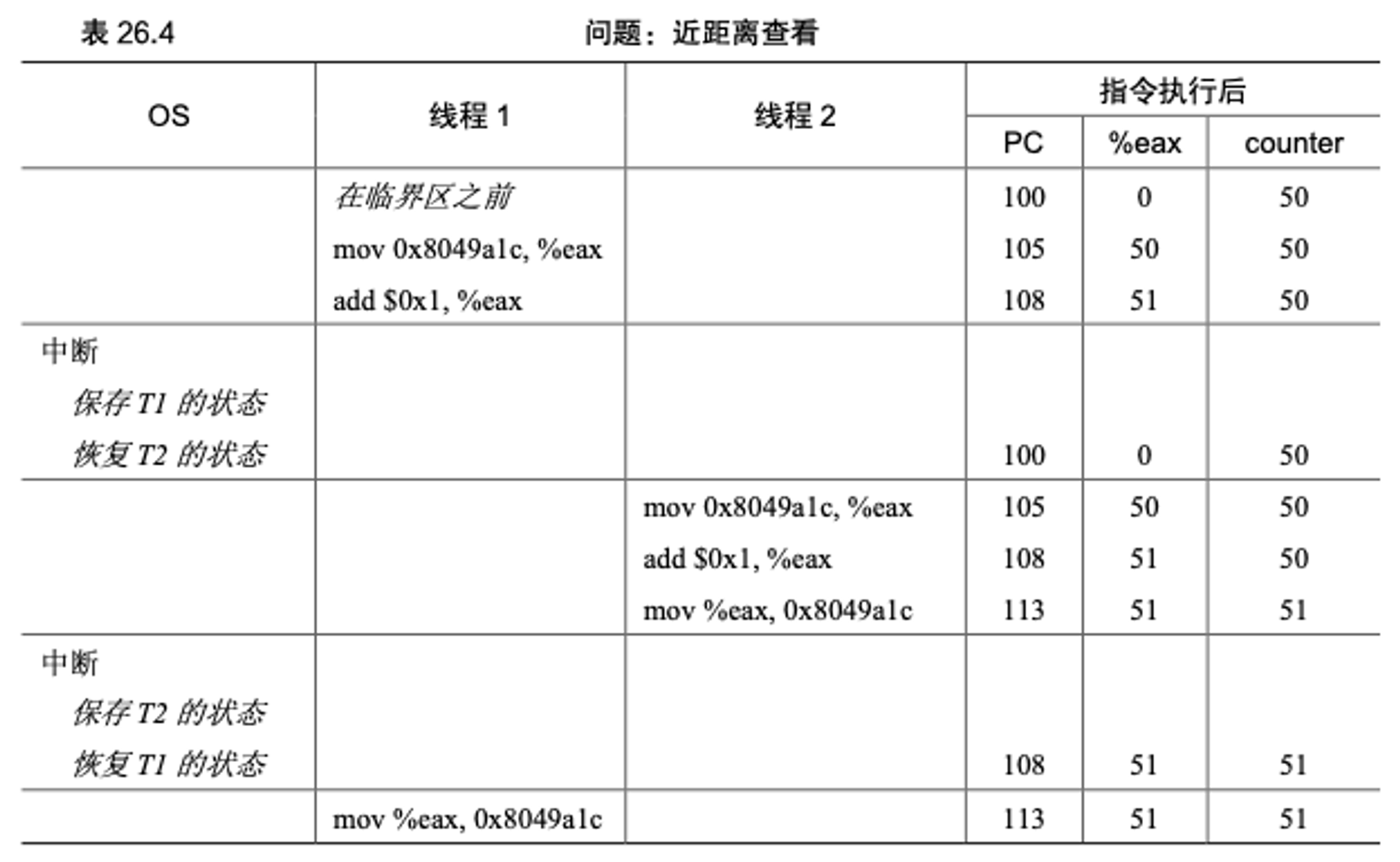
如上图所展示的情况就被称为竞态条件(race condition):结果取决于代码的时间执行。且每次的执行结果都是不同的。我们称这种为不确定的(indeterminate),而不是确定的(determinate)计算。不确定的计算就不能保证有确定的输出。
由于这段代码的多个线程有可能会导致竞态条件,因此我们将这段会导致竞态的代码称为临界区(ceitical section)。临界区是访问共享变量的代码片段,它一定不能由多个线程同时执行。
而其实我们想要的其实就是互斥(mutual exclusion)。它需要保证当一个线程在临界区内运行时,其它的线程将被组织进入临界区。
这些术语其实都是由Edsger Dijkstra 创造的,他是这个领域的先驱,且获得过图灵奖。他在1968关于“Cooperating Sequential Processes”对这些问题给出了很清晰的描述
原子性
如果要解决上述出现的竞态问题,有一种方式就是拥有更强大的指令,单步就可以完成的操作,避免不合时宜的中断,比如,下面这条超级指令怎么样。
假设这条指令是将一个值添加到内存的某个位置,并且硬件会保证它是以原子性(atomically)执行,它不会在指令的执行过程中中断。这是硬件给予我们的保证。
在这里,原子方式的意思是”作为一个单元“,有时我们说”全部或没有“。我们会希望以原子方式来执行3个指令的序列:
如果有能够一条指令就能做到这一点的话,我们可以发出这条指令。但是通常是不会有这样的指令。
因此,我们要做的要求硬件提供一些特殊指令,然后在这些指令上构建一个通用的集合,即所谓的同步原语(synchronization primitive)。通过使用这些硬件同步原语,再加上操作系统的一些帮助,我们就能够在构建多线程代码时,以同步和受控的方式来访问临界区,从而产生稳定的结果。
补充:关键并发术语
临界区、竞态条件、不确定性、互斥执行
- 临界区(critical section) 是访问共享资源的一段代码,资源通常是一个变量或者数据结构。
- 竞态条件(race condition) 出现在多个执行线程大致同时进入临界区时,它们都试图操作更新共享数据结构,会导致意想不到的结果。
- 不确定性(indeterminate) 程序受一个或多个竞态条件影响,程序的输出结果因运行而异,具体取决于哪些线程在何时执行。这导致结果是不确定的,而我们通常是期望计算机给出确定结果的。
- 为了避免这些问题,线程应该使用某种互斥(mutual exclusion)原语。这样可以保证只有一个线程进入临界区,从而避免掉竞态,从而产生确定的结果。
还有一个问题:等待另一个线程
刚刚我们提到的问题是两个线程都在操作同一个变量,因此需要为临界区支持原子性。但其实还有另外一种交互,即一个线程需要等待另一个线程。如一个执行I/O时进入了睡眠状态,当I/O完成时,这个进程又会被唤醒。
后续的章节我们不仅会学习如何构建同步原语来支持原子性,还要研究支持在多线程中常见的睡眠/唤醒交互机制。
将一系列动作原子化其实就是“全部或没有”。看上去,要么你希望组合在一起的所有活动都发生了,要么它们都没有发生。不会有中间状态。有时,将许多组合为单个原子动作称为事务(transaction),数据库中有这个概念。