



这一章我们讨论在常见的数据结构中使用锁。通过使用锁来使数据结构线程安全(thread safe),同时,如何在多线程同时访问该结构时,即并发访问(concurrently)时保证高性能。
并发计算器
如下是一个非并发的计数器。
这个计数器非常简单,但是没有保证线程安全,接下来我们来优化一下这个计数器,它也非常简单,它只是加了一把锁,在操作该数据的时候获取锁,操作完成时释放锁。
接下来我们来测试一下,加上锁之后的性能如何。如下是一个基准测试,每个线程更新同一个共享计数器固定次数,然后我们改变线程数。下图是运行1个线程到4个线程的总耗时,每个线程会更新100万次计数器。下图是4 核 Intel 2.7GHz i5 CPU 的 iMac的结果。

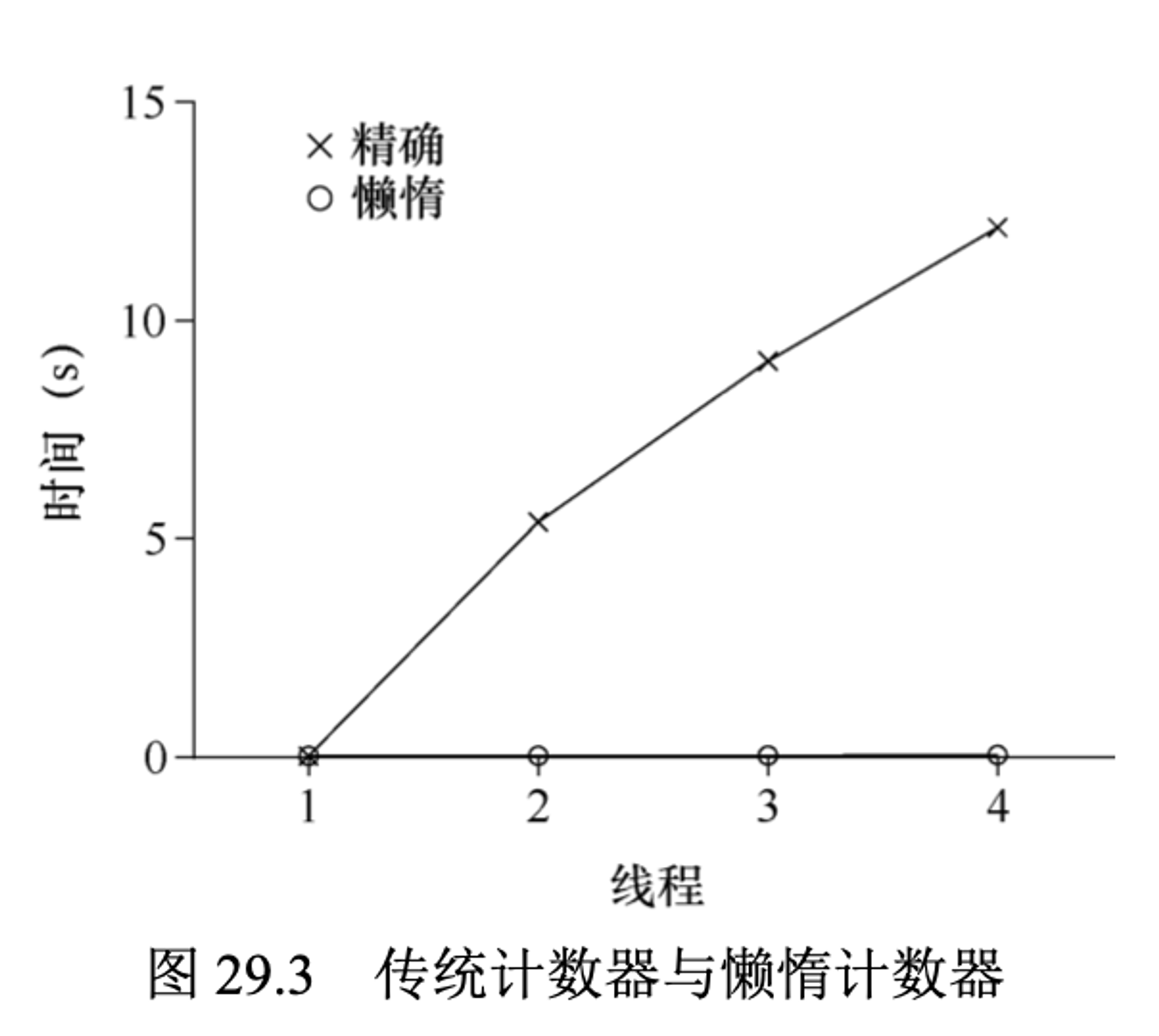
从图中可以看出,单线程完成100万更新很短(约0.03s),但是两个线程并发更新,每个都执行100万次,性能下降明显(超过5s+)。当线程更多时,这个结果会更差。
在理想情况下,我们是希望多线程和单线程能够一样快,如果能够达到这种状态则称为完美扩展(perfect scaling)。
懒惰计数器
懒惰计数器的是通过多个局部计数器和一个全局计数器实现的。每颗CPU都会有一个局部计数器,然后全局有一个全局的计数器。并且,每个局部计数器都有一个锁,全局计数器也有一个锁。
它的思想是这样的:如果一个核心上的线程想要对计数器进行加1,那么就操作这颗核心上的局部计数器就可以了。访问这个局部计数器是通过其对应的局部锁同步的。
当局部计数器会有一个阈值(S,表示sloppiness),当局部计数器的数字超过这个阈值时,就会将局部计数器的值更新到全局计数器,方法是获取全局锁,让全局计数器加上局部计数器的值。然后将局部计数器的值置零。
这个阈值S越小,则全局计数器的值越实时。S越大,扩展性强,离非懒惰的计数器偏差越大。
如下有一个表,是4颗CPU(L1,…,L2)的懒惰计数器的例子,此处的阈值设置为“5”,全局计数器的值是G
时间 | L1 | L2 | L3 | L4 | G(全局计数器) |
0 | 0 | 0 | 0 | 0 | 0 |
1 | 0 | 0 | 1 | 1 | 0 |
2 | 1 | 0 | 2 | 1 | 0 |
3 | 2 | 0 | 3 | 1 | 0 |
4 | 3 | 0 | 3 | 2 | 0 |
5 | 4 | 1 | 3 | 3 | 0 |
6 | 5→0 | 1 | 3 | 4 | 5(来自L1) |
7 | 0 | 2 | 4 | 5→0 | 10(来自L4) |
我们再来看这个懒惰计数器的性能,依旧是这个图,最底部的线是阈值S为1024时的懒惰计数器性能。4个处理器400万次的时间和一个处理器更新100万次的时间几乎一样。
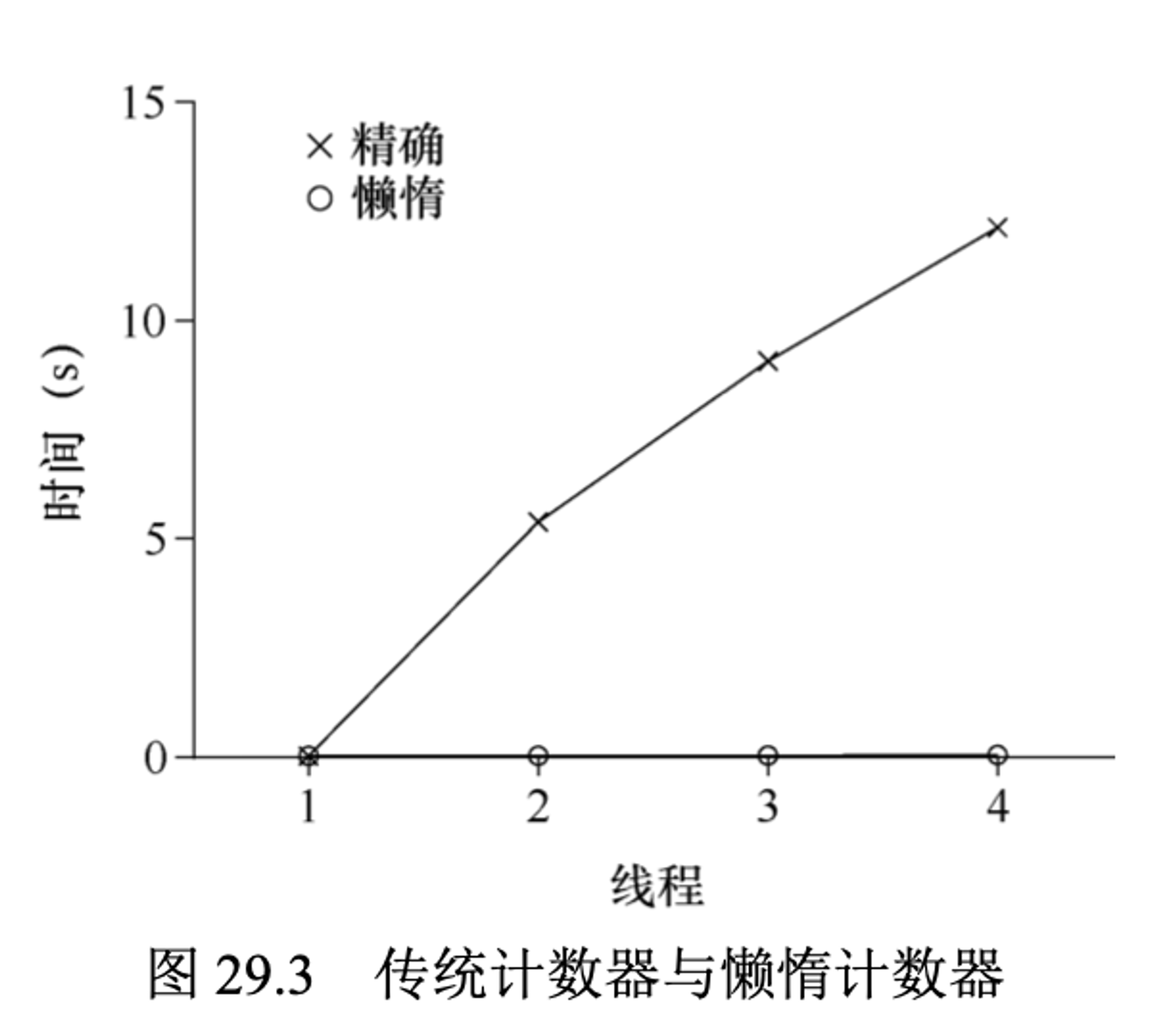
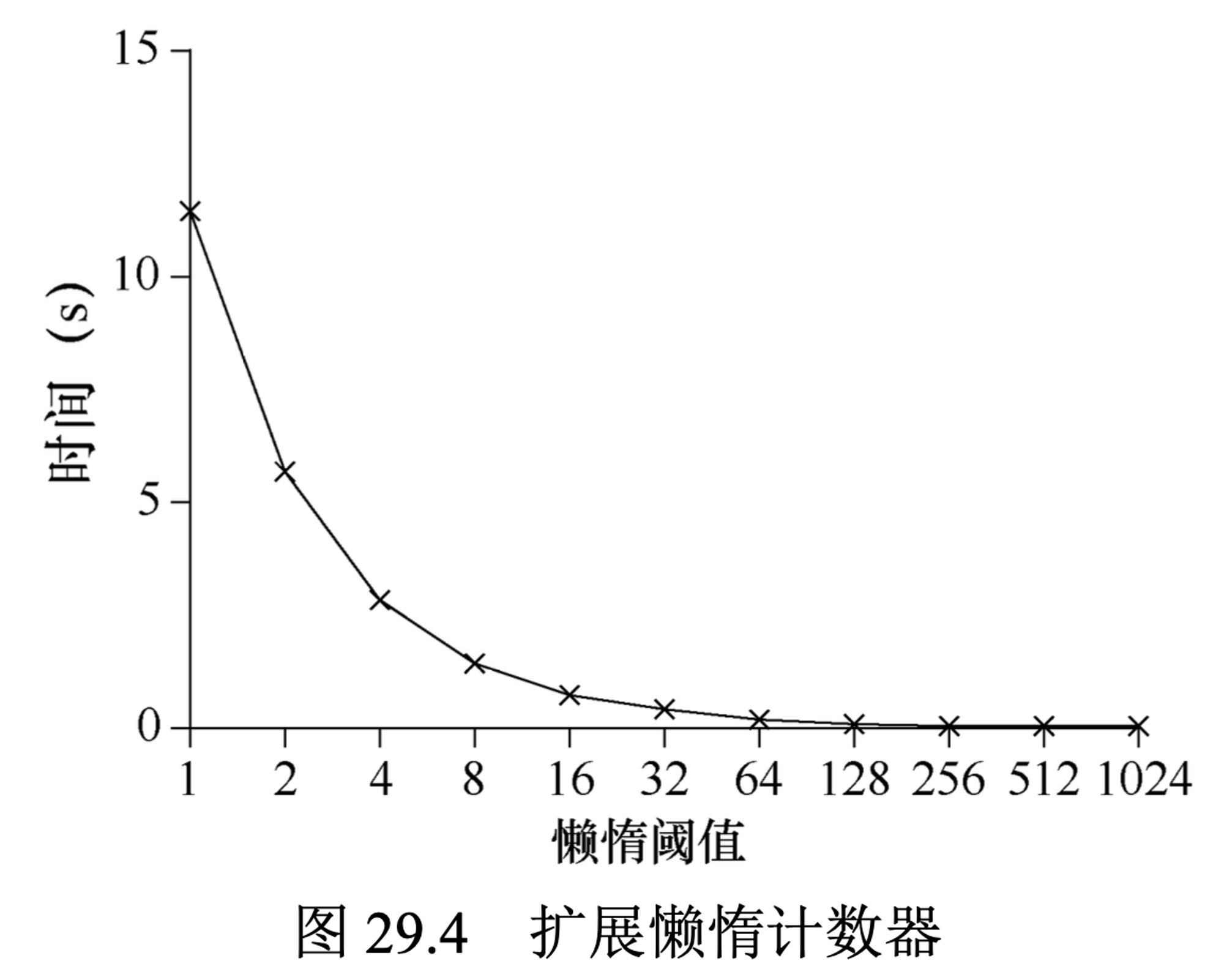
同时,阈值S的设置也很重要,如下图,是4颗CPU上的4个线程,分别增加计数器100万次。S越小,性能越差,全局计数器的精准度高。S越大,则性能越好,全局计数器的精准度低。懒惰计数器是在准确性和心性能之间折中。

如下是懒惰计数器的实现


并发链表
我们再来看一下链表,先从一个基础的实现开始,简单起见,只关注插入操作
从代码中可以看出,代码在函数入口处获取锁,结束时释放锁,如果malloc失败(极少情况),也需要释放锁。
因此,我们可以再对这个并发链表进行优化:重写插入和查找函数,并且避免在malloc失败的时候也需要释放锁。
我们可以这样调整,让获取锁和释放锁只在真正要进入临界区时发生。我们假定malloc是线程安全的,不会有并发问题。我们可以在malloc成功后再获取锁,具体代码如下。这样做减少了代码中获取锁,释放锁的地方。
尽管这样实现了一个基本的并发链表,但又遇到了扩展性不好的问题。研究人员发现在链表的并发技术中,有一种叫做过手锁(hand-over-hand locking,也叫做锁耦合,lock coupling)。
它是每个节点都有一个锁,而不是像上述一样整个链表都一个锁。遍历链表的时候,会先抢占下一个节点的锁,然后释放当前节点的锁。
概念上来说,过手锁好像有点道理,它增加了链表操作的并发程度。但实际的效率却有些下降了,遍历的时候,每个节点获取锁,释放锁的开销太大,会比单锁(一把大锁)的方案效率低很多。即使有大量的线程和超大的链表,这种方案也不一定会比单锁的方案更快。因此,有些杂合方案(一定数量的节点用一个锁)值得去研究。
更多并发不一定快
如果方案导致了大量的开销(如,频繁获取锁,释放锁),那么高并发就没什么意义。如果更简单的方案会在很少的情况才用到高开销的调用,通常这种更简单的方案会更高效。增加更多的锁和复杂性可能会适得其反。话虽如此,但是具体情况具体分析:可以两种方案都实现出来(简单的少一些并发,复杂的多一些并发),测试它们的实际表现。
并发队列
刚刚我们学习了一个标准的方法来创建并发数据结构:使用一把大锁。但是对于队列来说,我们将不使用这种方案。下面是Michael和Scott设计的、更并发的队列。
这个设计一共有两个锁,一个头锁,一个尾锁。这两个锁的设计使得入队和出队操作可以并发执行,因为入队只操作tail(尾)锁,出队只操作head(头)锁。其中一个小技巧是在初始化时插入了一个假节点,这个假节点分开了头尾操作。
队列在多线程中应用很广,我们这个队列不能完全满足所有程序的需求。还有一种更加完善的有界队列,可以在队列满了,或者空了的时候让线程等待。在后续更深入的学习条件变量时会看到。
并发散列表(hash表)
接下来,我们再来学习最后一个应用广泛的并发数据结构,散列表(hash表,在高级语言里面也叫对象),我们目前暂时先只关注不需要调整大小的散列表(bucktes = 101)。
这个散列表我们会用到我们之前实现的并发链表,性能特别好。
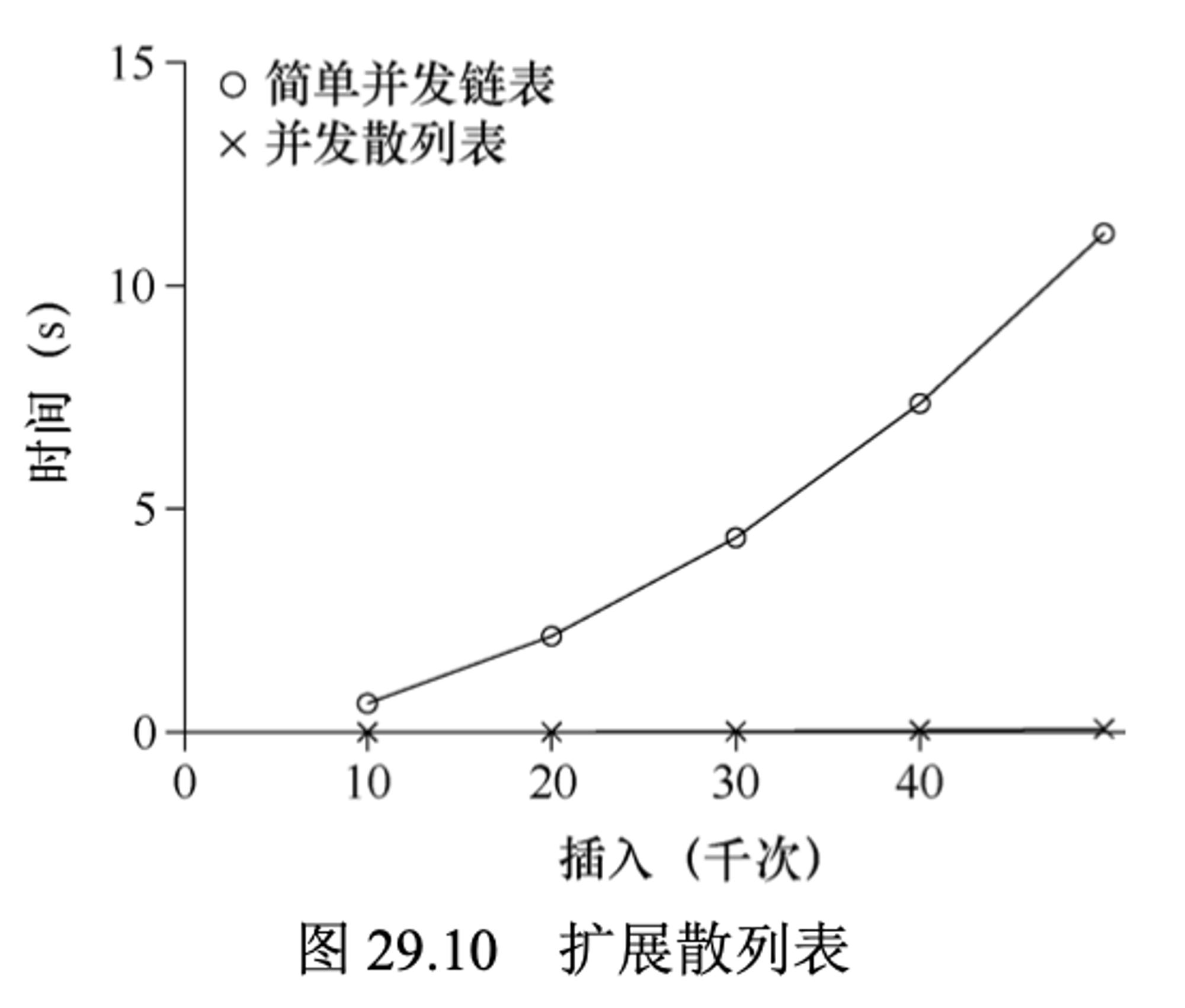
下图展示了在4CPU的iMac,4个线程,每个线程分别执行1万~5万次并发更行的性能,同时与单链表进行了比较。可以看出,这个简单的并发散列表扩展性能极好,而链表则相反。

避免过早的优化
我们在实现并发数据结构时,会先从最简单的方案开始,也就是加一把大锁来同步。这样很简单就构建了一个正确的锁。当发生了性能问题时,再对它进行改进,只要优化到满足需求即可。正如Knuth的著名说法“不成熟的优化是所有坏事的根源。”
许多操作系统,在最初过渡到多处理器时都是用一把大锁,包括 Sun 和 Linux。在 Linux 中,这个锁甚至有个名字,叫作 BKL(大内核锁,big kernel lock)。这个方案在很多年里都很有效,直到多 CPU 系统普及,内核只允许一个线程活动成为性能瓶颈。终于到了为这些系统优化并发性能的时候了。Linux 采用了简单的方案,把一个锁换成多个。Sun 则更为激进,实现了一个最开始就能并发的新系统,Solaris。这些信息可以通过阅读Linux和Solaris内核来了解更多。