



在20世纪90年代早期,由John Ousterhout教授和研究生Mendel Rosenblum领导的伯克利小组开发了一种新的文件系统,称为日志结构文件系统。它的设计思想是将所有的文件操作都记录在一个日志中,然后按照顺序写入磁盘。这种设计可以提高文件系统的性能和可靠性,因为它可以减少磁盘寻道时间和减少数据丢失的可能性。LFS已经被广泛应用于许多操作系统和存储系统中。
它们这样做的动机是基于以下观察
1. 内存不断增长:
随着内存越来越大,可以在内存中缓存更多数据。随着更多数据的缓存,磁盘流量将越来越多地由写入组成,因为读取将在缓存中进行处理。因此,文件系统性能很大程度上取决于写入性能
2. 随机I/O性能与顺序I/O性能之间存在巨大的差距,且不断扩大:传输带宽每年增加50%~100%:
寻道和选择延迟成本下降的很慢,可能每年5%~10%。因此,如果能够以顺序方式使用磁盘,则可以获得巨大的性能提升,随着时间的推移而增长。
3. 现有文件系统在许多常见工作负载上表现不佳:
例如,FFS会执行大量写入,以创建大小为一个块的新文件:一个用于新inode,一个用于更新inode位图,一个用于文件所在的目录数据块,一个用于目录inode以更新它,一个用于新数据块,它是新文件的一部分,另一个是数据位图,用于数据块标记为已分配。因此,尽管FFS会将所有这些快放在同一个块组中,但FFS会导致许多短寻道和随后的旋转延迟,因此性能远远低于峰值顺序带宽。
4. 文件系统不支持RAID:
例如,RAID-4和RAID-5具有小写入问题(small-write problem),即对单个块的逻辑写入会导致4个物理I/O发生。现有的文件系统不会试图避免这种最坏情况的RAID写入行为。
因此,理想的文件系统会专注于写入性能,并尝试利用磁盘的顺序带宽。此外,它在常见的工作负载上表现良好,这种负载不仅写出数据,还经常在更新磁盘上的元数据结构。最后,它可以在RADI和单个磁盘上都运行良好
这个新型的日志结构文件系统,Rosenblum和Ousterhout将其称为LFS,是日志结构文件系统(Log-structured File System)的缩写。写入磁盘时,LFS首先将所有更新(包括元数据!)缓冲在内存段中。当段已满时,他会在一次长时间的顺序传输写入磁盘,并传输到磁盘的未使用部分。LFS永远不会覆写原有数据,而是始终将段写入空闲位置。由于段很大,因此可以有效地使用磁盘,并且文件系统的性能接近其峰值。
关键问题:如何让所有写入都变成顺序写入?
文件系统如何将所有写入转换成顺序写入?对于读取,此任务是不可能的,因为要读取的所需块可以能是磁盘上的任何位置。但是,对于写入,文件系统总是有一个选择,而这正是我们希望利用的选择。
按顺序写入磁盘
因此,我们遇到了第一个挑战:如果将文件系统状态的所有更新转换为磁盘的一系列顺序写入?为了更好地理解这一点,让我们举一个简单的例子。想象一下,我们正在将数据块D写入文件。将数据块写入磁盘可能会导致以下磁盘布局,其中D写在磁盘地址A0:


但是,当用户写入数据块时,不仅是数据块被写入磁盘:还有其它需要更新的元数据(metadata)。在这个例子中,让我们讲文件的inode(I)也写入磁盘,并将其指向数据块D。写入磁盘时,数据块和inode看起来像下图这样(注意inode看起来和数据块一样大,但通常情况并非如此。在大多数系统中,数据块大小为4KB,而inode小得多,大约128B)


简单地将所有更新(例如数据块、inode等)顺序写入磁盘的这一基本思想是LFS的核心。如果你理解这一点,就抓住了基本的想法。但就像所有复杂的系统一样,魔鬼藏在细节中。
实现的细节很重要:
所有有趣的系统都包含一些一般性的想法和一些实现细节。有时,在学习这些系统时,你会对自己说,”哦,我已经理解了它的核心思想,其它的只是一些细节“。你这样想时,对事情是如何运作的只是一知半解。不要这样做!
很多时候,细节至关重要。正如我们在LFS中看到的那样,一般的想法很容易理解,但要真正构建一个能工作的系统,必须仔细考虑所有棘手的情况。
顺序而高效的写入
遗憾的是,单单顺序吸入磁盘并不足以保证高效写入。例如,假设我们在时间T向地址A写入一个块。然后等待一会儿,再向磁盘A+1(下一个块地址按顺序),但是在时间T+δ。遗憾的是,在第一次和第二次写入之间,磁盘已经旋转。当你发出第二次写入时,磁头下方不一定是A+1的位置,它可能需要等待一大圈旋转(具体地说,如果旋转需要时间 Trotation,则磁盘将等 待 Trotation−δ,然后才能将第二次写入提交到磁盘表面)。因此,你可能希望看到简单地按顺序写入磁盘不足以实现最佳性能。实际上,你必须向驱动器发出大量连续写入(或一次大写入)才能获得良好的写入性能。
为了达到这个目的,LFS使用了一种称为写入缓冲(write buffering)的古老计数。在写入磁盘之前,LFS会跟踪内存中的更新。收到足够数量的更新时,会立即将它们写入磁盘,从而确保有效使用磁盘。
写入缓冲是LFS非常重要的组成部分,它用于缓存文件系统中的写入操作,以提高文件系统的性能。具体来说,当一个文件被修改时,LFS会将修改操作记录在日志中,并将修改后的数据块写入写入缓冲中。写入缓冲通常是一个内存缓冲区,它可以快速地写入和读取数据,因此可以提高文件系统的写入性能。
在LFS中,写入缓冲通常被分成多个块,每个块的大小通常是一个磁盘块的大小。当一个块被写满时,LFS会将它写入磁盘上的一个新的数据块中,并将数据块的地址记录在日志中。这样,即使系统崩溃或断电等异常情况发生,也可以通过读取日志来恢复文件系统的状态。
写入缓冲还可以通过一些技术来提高文件系统的性能。例如,LFS可以使用写入缓冲来实现延迟写入,即将多个写入操作合并成一个大的写入操作,以减少磁盘访问次数。
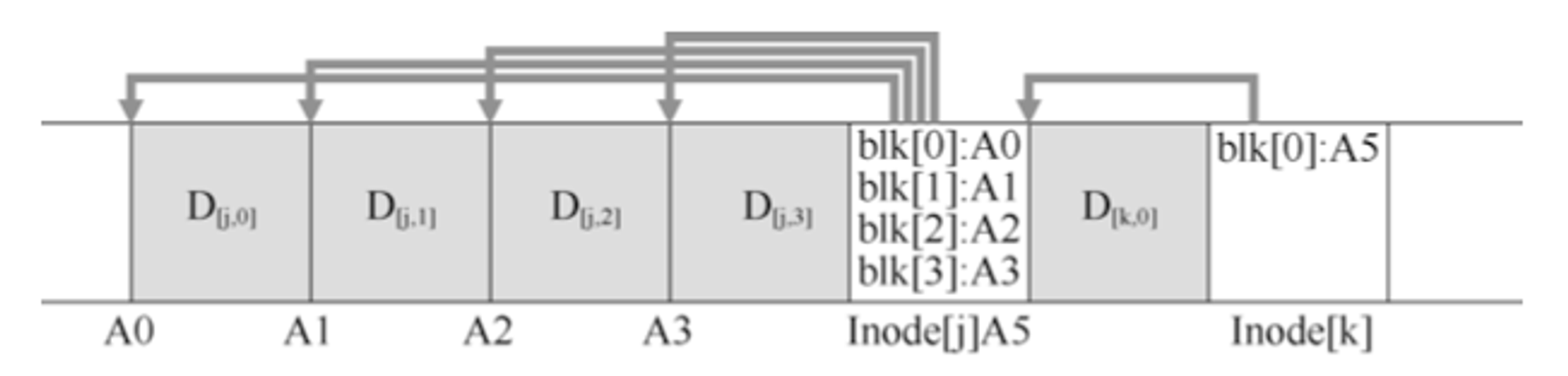
下面是一个例子,其中LFS将两组更新缓冲到一个小段中。实际段更大(几MB)。第一次更新是对文件j的4次块写入,第二次是对文件k的一次块写入。然后LFS立即将整个7个块的段提交到磁盘。这些块的磁盘布局如下:

要缓冲多少
这提出了以下问题:LFS在写入磁盘之前应该缓冲多少次更新?答案当然取决于磁盘本身,特别是与传输速率相比定位开销有多高。有关类似的分析,请参阅FFS相关的章节。
例如,假设在每次写入之前定位(即选择和寻道开销)大约需要。进一步假设磁盘传输苏律是。在这样的磁盘上运行时,LFS在写入之前应该缓冲多少?
考虑这个问题的方法是,每次写入时,都需要支付固定的定位成本。因此,为了摊销(amortize)这笔成本,你需要写入多少?写入越多就越好(显然),越接近达到峰值带宽。
为了得到一个具体的答案,假设要写入MB数据。写数据块的时间是定位时间的加上D的传输时间(D/R_{peak}),即

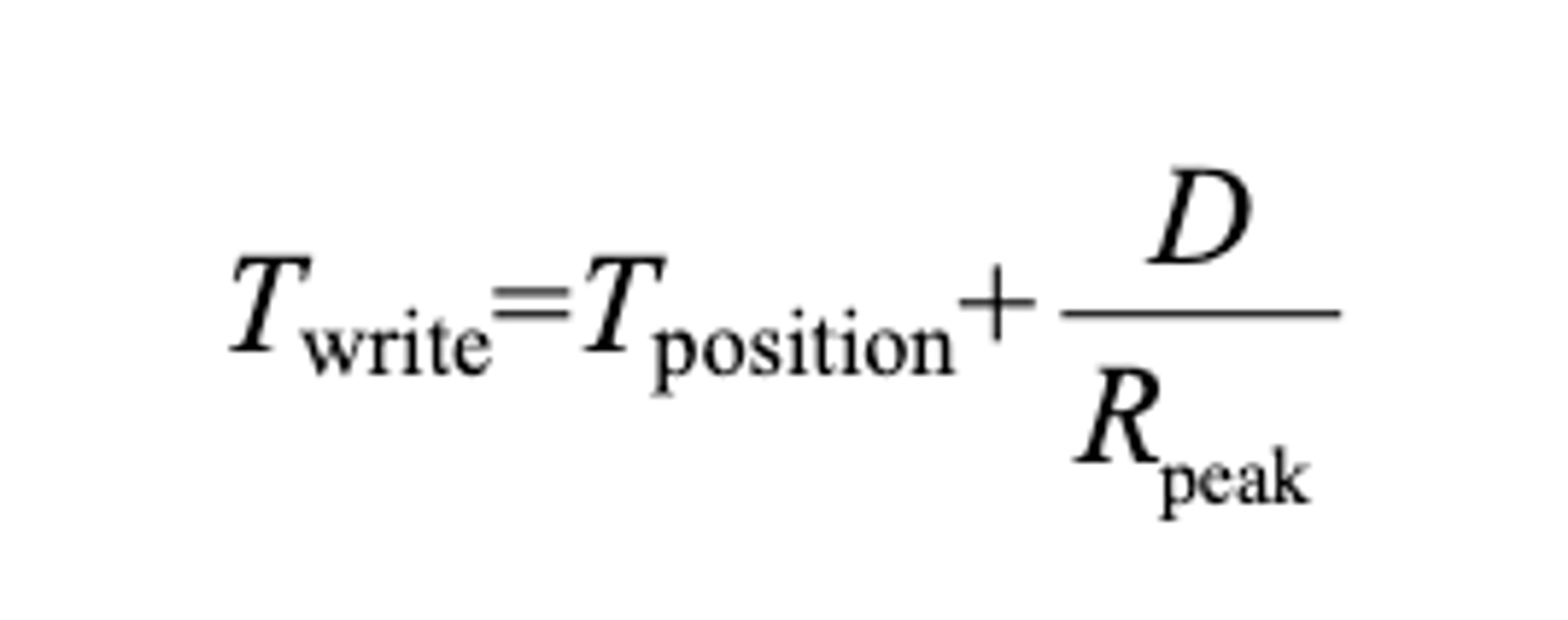
因此,有效写入速率()就是写入的数据量除以写入的总时间,即

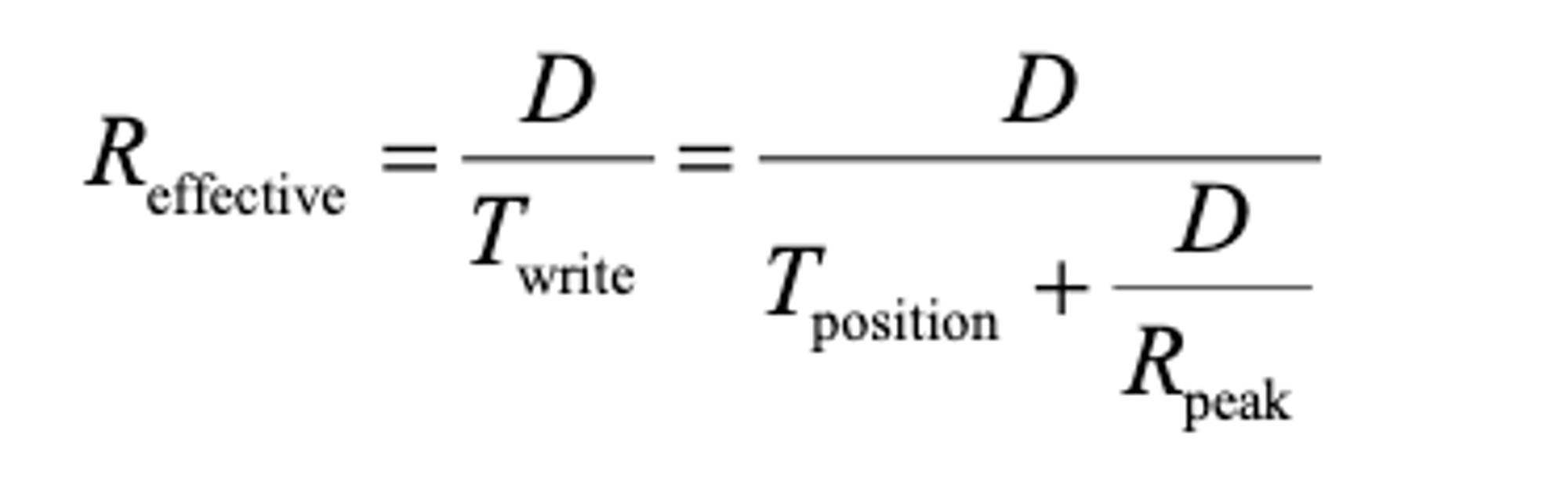
我们感兴趣的是,让有效速率()接近峰值速率。具体而言,我们希望有效速率与峰值速率的比值是某个分数F,其中0<F<1(典型F可能是0.9,即峰值速率的90%)。用数学表示,这意味着我们需要
此时,我们可以解出D:

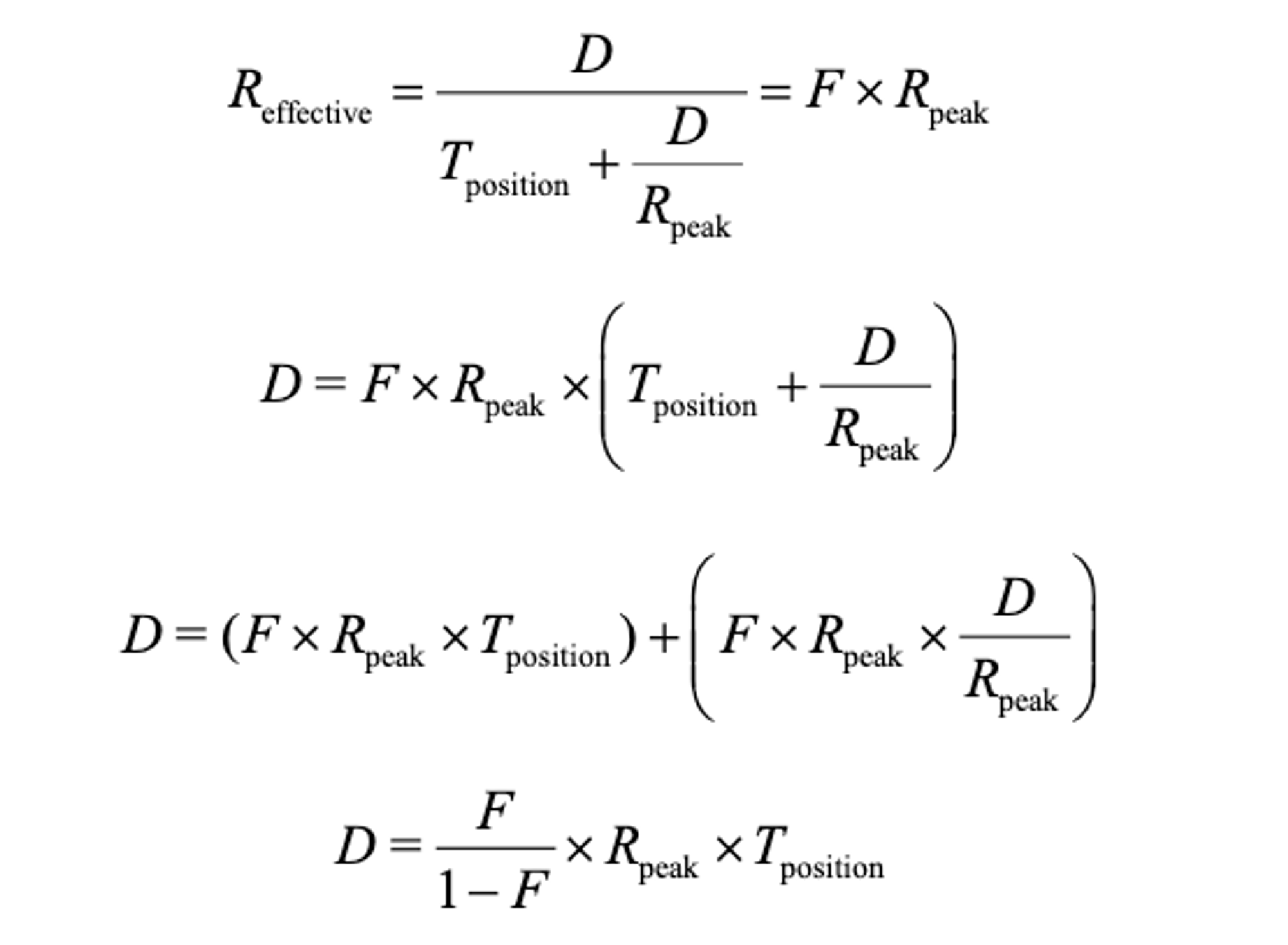
举个例子,一个磁盘的定位时间为10ms,峰值传输率为100MB/s。假设我们希望有效带宽达到峰值的10%(F=0.9)。在这个情况下,D=0.9*100MB/s*0.01s=9MB。请尝试一些不同的值,看看需要缓冲多少才能达到峰值带宽,达到95%的峰值需要多少,达到99%呢?
问题:查找inode
要了解如何在LFS中查找inode,让我们简单回顾一下如何在典型的UNIX文件系统中查找inode。在典型的文件系统(如FFS)甚至老UNIX文件系统中,查找inode很容易,因为它们以数组形式组织,并放在磁盘的固定位置上。
例如,老UNIX文件系统将所有inode保存在磁盘的固定位置。因此,给定一个inode号和起始地址,要查找特定的inode,只需将inode号乘以inode的大小,然后将其加上磁盘数组的起始地址,即可计算其确切的磁盘地址。给定一个inode号,基于数组的索引是快速而直接的。
在FFS中查找给给定inode号的inode会稍微复杂一点,因为FFS将inode表拆分为块并在每个柱面组中放置一组inode。因此,必须知道每个inode块的大小和每个inode的起始地址。之后的计算类似,也很容易。
在LFS中,这会更为困难。为什么?好吧,我们现在已经将inode分散在整个磁盘上!更糟糕的是,我们永远不会覆盖,因此最新版本的inode(即我们想要的那个)会不断移动。
通过间接解决方案:inode映射
这个inode映射的设计有些怪怪的,需要结合LFS的日志理解,单单理解这个inode映射会觉得它有些多次一举,因为inode映射也需要占用空间,它同样是分散在磁盘上的。
我们知道,当我们查找某个文件时,通常是通过文件路径来获取该文件的inode号。文件路径是由目录和文件名组成的,每个目录都有一个唯一的inode号,因此可以通过遍历目录树来获取文件的inode号。
在LFS中,目录的inode也是随机分布的,因此遍历目录树的过程会比较困难。为了解决这个问题,LFS引入了一种称为目录索引(directory index)的数据结构。目录索引是一种B树,用于记录目录中的所有文件和子目录。每个目录都有一个目录索引,其中包含了该目录下所有文件和子目录的元数据信息和inode号。当需要遍历目录树时,LFS会先读取目录的目录索引,然后按照B树的遍历方式遍历目录树。需要注意的是,由于目录索引本身也需要占用磁盘空间,因此LFS需要在性能和空间利用率之间做出权衡。同时,目录索引也需要定期进行维护和优化,以保证其性能和可靠性。
当我们知道inode号之后,需要去找到具体的inode,因为我们将所有的inode分散在了磁盘上。如果要从磁盘上找到具体的位置,会有些困难。因此,LFS的设计者设计了一个inode映射(inode mpa,imap)的数据结构。它是一个inode号到inode具体块的映射。每当有一个文件写入到磁盘时,会有一个相对应的imap也会写入。
既然imap也会写入,那就说明imap是保持持久的。这样做允许LFS在崩溃时仍能记录inode位置,从而按设想运行。因此有一个问题:imap应该驻留在磁盘上的哪个位置?
我们想到最简单的方是将它放在磁盘的固定位置。遗憾的是,由于它经常更新,因此需要更新文件结构,然后写入imap,因此性能会收到影响(每次的更新和imap的固定位置之间,会有更多的磁盘寻道)。
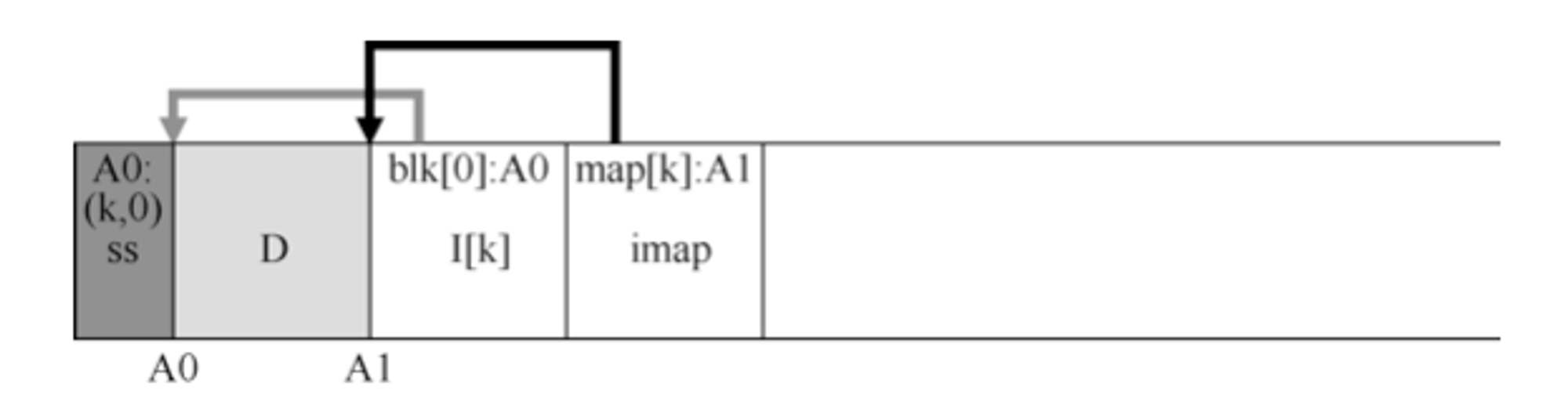
LFS的做法是,将inode的映射块放在它写入所有其它新信息的位置旁边。因此,当将数据块追加到文件k时,LFS实际上将新数据块,inode和inode映射块一起写入磁盘,如下所示:

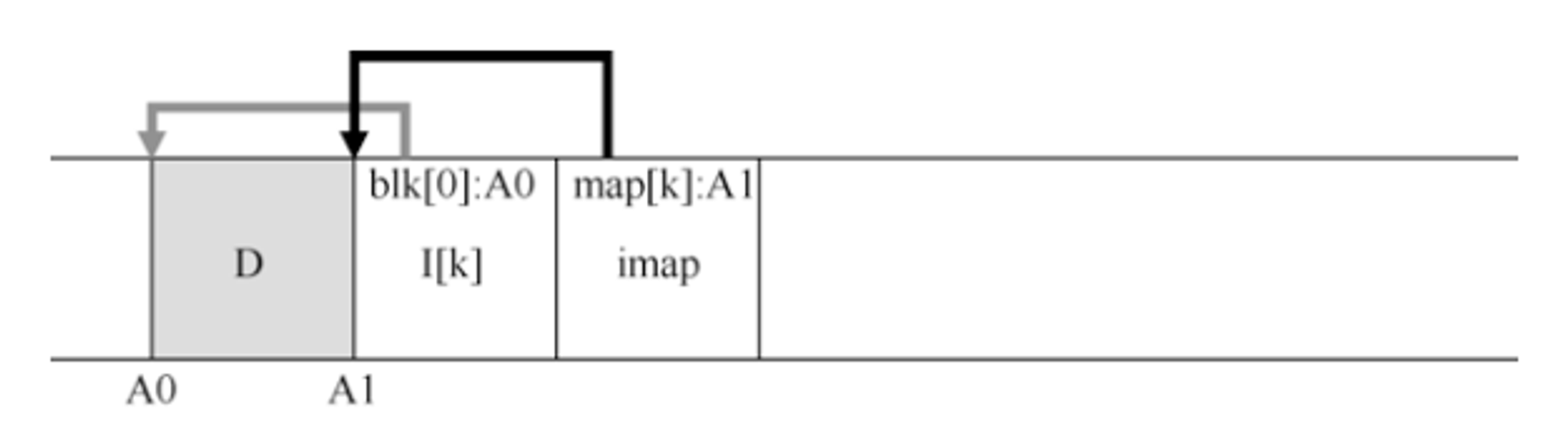
在该图中,imap数组存储在标记为imap的块中,它记录中inode k位于磁盘地址A1。接下来,它的inode告诉LFS它的数据块D在地址A0。
检查点
检查点(checkpoint region,CR)是文件系统状态的快照,包括所有的元数据信息和数据块。它并非日志,日志是记录文件系统的写入操作的,而检查点是记录文件系统状态, 在磁盘上的位置是确定的。
检查点会定期更新(例如每30s左右),创建一次检查点需要对磁盘进行一次完整的扫描,为了避免消耗过多的系统资源,LFS通过会采用一些策略,例如增量检查点和快速检查点来减少开销。
当加入检查点之后,它会如下图所示,如果是一个真正的文件系统会有更大的CR(事实上,它将有两个,我们稍后会理解),许多imap块,当然还有更多的inode、数据块等。

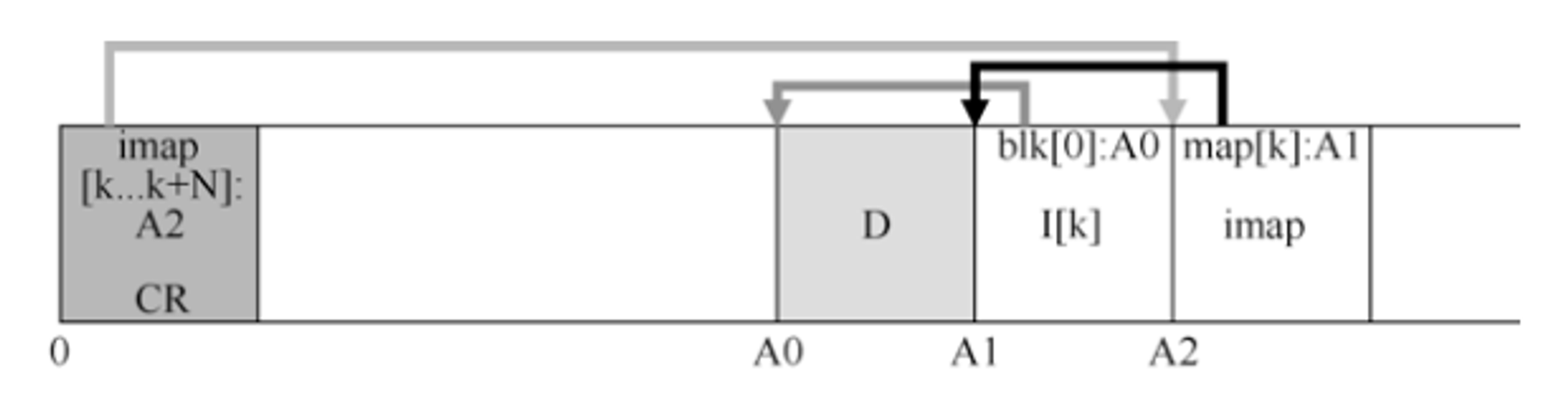
这一小节感觉书上没有解释好,也可能是翻译的原因,需要问GPT以了解更多的内容。
从磁盘读取文件的流程
为了确保我们已经理解了LFS的工作原理,现在让我们来看看从磁盘读取文件时必须发生的事情。我们从内存中没有任何东西开始。假设我们需要读取inode号为3的文件。
我们会先读取检查点区域(因为内存缓存为空),将检查点中包含inode的映射指针读取到,然后将其缓存在内存。
当找到inode块之后,就知道数据块的具体地址了,这个去读方法和典型的UNIX文件系统一致,即使用直接指针或间接指针或双重间接指针。
在此之后,如果又发生了一个文件读取,LFS会先在imap中查到inode号到inode磁盘地址的映射(此时imap被缓存在内存中)。
目录会如何处理
到目前为止,我们通过仅考虑inode和数据块,简化了讨论。但是,要访问文件系统中的文件,我们一般是通过文件路径来访问的(
/home/remzi/foo),其中出现了目录,那么对于目录数据,LFS是如何存储的呢。对于目录的inode结构来说,和传统的UNIX文件系统基本相同,因为目录只是(inode号)映射的集合。例如,在磁盘上创建文件时,LFS会写入新的inode,数据块,以及引用此文件的目录数据及其inode。请注意,LFS将在磁盘上按顺序写入(在缓冲更新一段时间后)。因此,在目录中创建文件foo,将导致磁盘上的以下新结构:

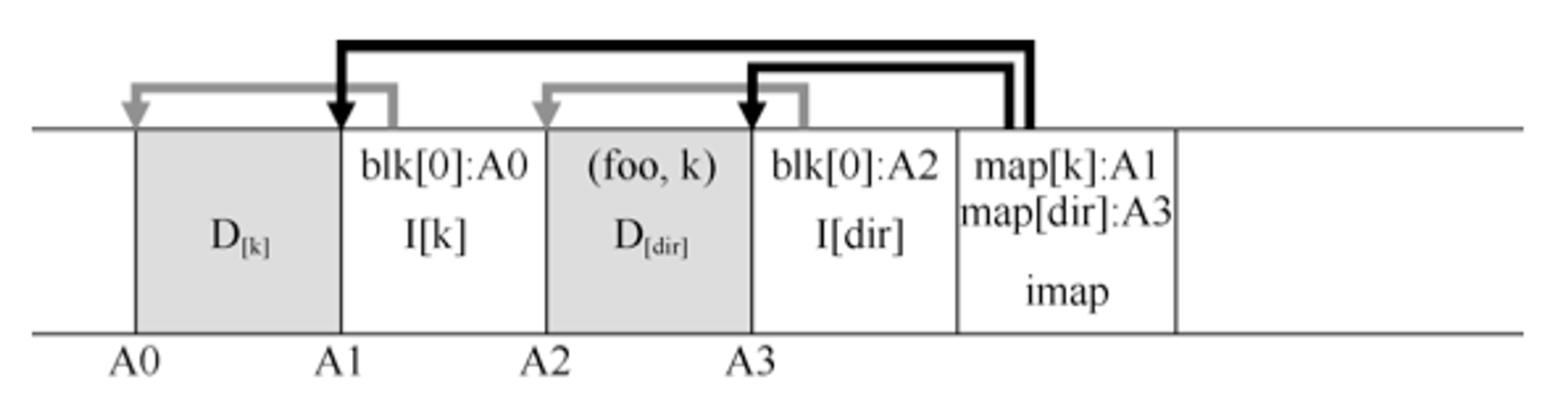
你会注意到,在这个imap中,它包含了目录dir以及新创建文件 inode号k的位置信息。因此,如果你要访问文件foo(inode号f)时,你需要先查看dir的inode映射(它通常缓存在内存中),找到目录dir(A3)的inode的位置。然后读取目录的inode(图中右边第二个块),其中可以获取到目录数据的位置(A2)。读取此数据块找到了foo的映射(foo,k)。然后在此查阅inode映射,找到inode号k(A1)的位置,最后在地址A0处读取所需的数据块。
inode映射还解决了LFS中存在的另一个严重问题,称为递归更新问题(recursive update problem)。然和永远不会原地更新的文件系统(例如LFS)都会遇到该问题,它们将更新移动到磁盘上的新位置。
具体来说,每当更新inode时,它在磁盘上的位置都会发生变化。如果我们不小心,这也会导致对指向该文件的目录的更新,然后必须更改该目录的父目录,以此类推,一路沿文件系统树向上。
LFS巧妙地避免了inode映射的这个问题。即使inode的位置可能会发生变化,更改也不会反映在目录本身中。事实上,imap结构被更新,而目录保持相同的名称到inumber的映射。因此,通过间接,LFS避免了递归更新问题。
新问题:垃圾收集
你可能注意到了LFS的另一个问题;它会反复将最新版本的文件(包括其inode和数据)写入到此磁盘的新位置。这意味着,整个磁盘上可能会保留多份旧版本的文件结构(数据块,inode等)。我们将这些旧版本称为垃圾(garbage)。
例如,假设有一个inode号k引用的现有文件,该文件指向单个数据块D0。我们现在覆盖该块,生成新的inode和新的数据块。由此禅师的LFS磁盘布局看起来像这样(注意,简单起见,我们省略了imap和其它结构。还需要将一个新的imap大块写入磁盘,以指向新的inode):

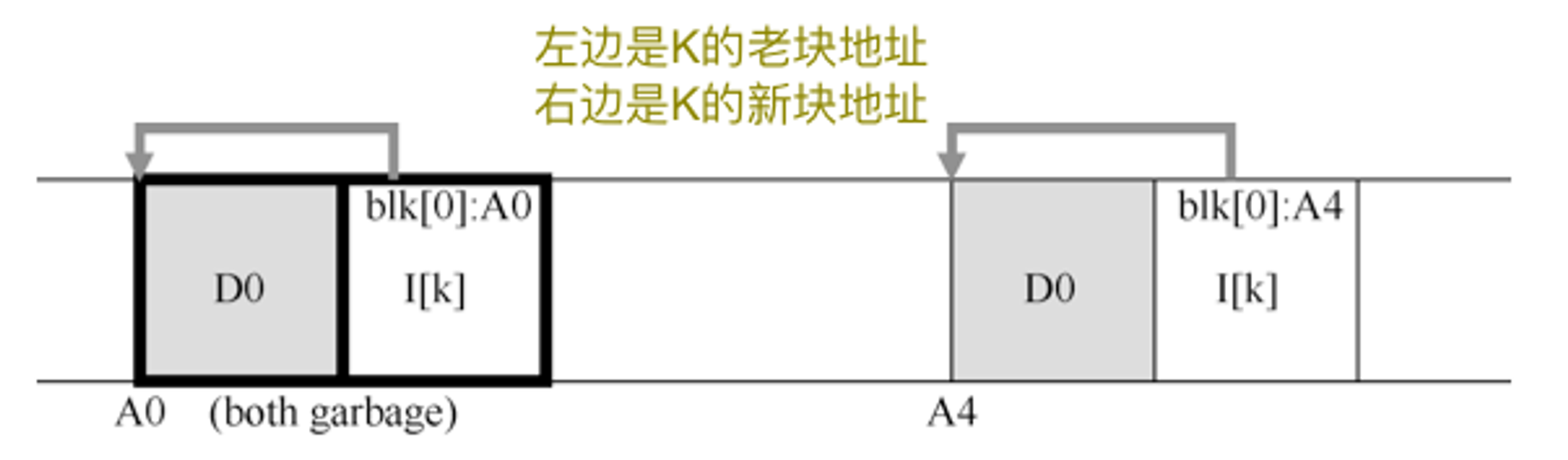
在上图中,我们可以看到inode的数据块在磁盘上的两个版本,左边是那个是旧的,右边的是新的,因此是活的(live)。对于覆盖数据块的简单行为,LFS必须持久许多新结构,从而在磁盘上留下上述块的旧版本。
再来举一个例子,这个例子是对文件的追加,假设我们将一个块添加到该原始文件k中。这种情况,inode 会生成一个新的,这个新的inode会包含之前旧的数据块指向。因此,旧的数据块可以正常引用,但它与当前文件系统分离:

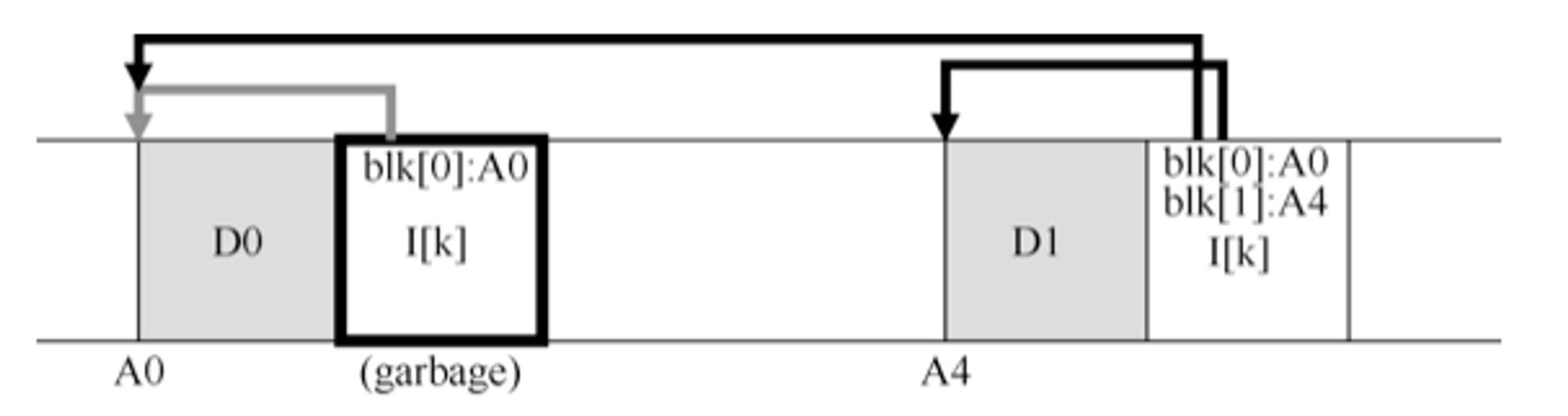
那么,我们应该如何处理这些旧版本的inode、数据块等呢?
一种方式是:可以保留那些旧版本并允许用户恢复文件的版本(例如,但他们以外覆盖或删除文件是,可以很好的恢复文件)。这样的文件系统称为版本控制文件系统(versioning file system),因为它跟踪文件的不同版本。
LFS的做法是:只保留文件的最新版本。因此,LFS会在后台定期查找文件数据,索引节点和其它结构的旧的死版本,并清理(clean)它们。清理后会使得磁盘上的块再次变为空闲,以便在后续写入中使用。请注意,清理过程是垃圾收集(garbage collection)的一种形式,这种技术在编程语言中出现,可以自动为程序释放没有使用的内存。
还记得我们之前讨论的段吗,LFS中对磁盘的写入是按大段写入的。它在清理垃圾数据的过程中起了很重要的作用。想象一下,如果LFS清理程序在清理过程中简单地释放单个数据块,索引节点等,会发生什么。结果是:文件系统在磁盘上分配的空间出现了空闲洞(hole)。写入性能会大幅下降,因为LFS无法找到一个大块的连续区域,以便顺序地写入磁盘,获得高性能。
因此,LFS清理程序是按段工作的,从而为后续写入清理出大块空间。基本清理过程的工作原理如下。LFS清理程序定期读入许多旧的(部分使用的)段,确定哪些块在这些段中存在,然后写出一组新的段,只包含其中活的块,从而释放旧块用于写入。具体来说,我们预期清理程序读取M个现有段,将其内容打包(compact)到N个新段(其中N<M),然后将N段写入磁盘的新位置。然后释放旧的M段,文件系统可以使用它们进行后续写入。
但是,我们现在有两个问题。第一个是机制:LFS如何判断段内的哪些块是活的,哪些块已经死了?第二个策略:清理程序应该多久运行一次,以及应该选择清理哪些部分?
确定块的死活
LFS 的垃圾清理是以段为单位进行的。也就是说,如果一个段中有一些不活跃的数据块,但是还有一些活跃的数据块,那么整个段都不能被清理掉。
我们接着来看一下这个问题,给定一个磁盘段中地址为A的数据块D,LFS需要能够确定这个D块是否存活。为了能够达到这个要求。LFS会在每个段中加上一些描述信息,称为段摘要块(segment summary block),这个段摘要块包含了该段中所有数据块的 inode 号和偏移量信息,以及一些其他的元数据信息,如段的序号、大小、时间戳等。
其中值得注意的是偏移量,它是确定一个块是否存活的关键,偏移量实际上是一个指向数据块在文件中位置的指针,它记录了数据块在文件中的偏移量。在垃圾收集中,LFS 通过偏移量可以快速地定位数据块所属的文件和位置,从而判断该数据块是否还被引用。因此,可以将偏移量看作是一个反向指针,它指向了数据块所属的文件和位置,帮助垃圾收集程序快速地找到数据块的引用情况。
当有了摘要段之后,确定块的死活就很简单了,具体来说,LFS 会检查每个数据块的 inode 号和偏移量信息,看它是否在任何一个文件中被引用。如果没有被引用,那么这个数据块就是不活跃的,可以被清理掉。下面伪代码总结了这个过程:
下面是一个描述机制的图,其中段摘要块(标记为SS)记录了地址A0处的数据块,实际上文件k在偏移量0处的部分。通过检查imap的k,可能找出inode,并且看到它确实指向该位置。

LFS还在一些场景下进行了一些优化,可以更快速的确定块是否死活。例如,当一个文件被截断或删除时,LFS会增加其版本号(version number)这个版本号在摘要段块中会保存,并在imap中记录新版本号。
那么,对于这种场景,通过这个段中一个块的版本号去和文件的版本号去对比,就能够知道整个段中的数据是否活跃,这样可以减少该段中其它块的比对过程,
策略问题:要清理哪些块,何时清理
确定清理哪些块是一个比较复杂的问题,需要考虑多个因素,如数据块的引用情况、段的热度、磁盘空间的使用情况等。在 LFS 中,通常采用以下几种策略来确定清理哪些块:
1. 基于引用计数的策略:
LFS 可以通过记录每个数据块的引用计数来判断哪些块是活跃的,哪些块是不活跃的。当一个数据块被引用时,它的引用计数会增加;当一个数据块不再被引用时,它的引用计数会减少。当引用计数为 0 时,该数据块就可以被清理掉。这种策略可以有效地清理不活跃的数据块,但是需要额外的空间来记录引用计数,可能会影响性能。
2. 基于段热度的策略:
LFS 可以通过记录每个段的热度来判断哪些段是热的,哪些段是冷的。热段通常包含了经常被访问的数据块,因此可以延迟清理这些段,以便更多的数据块被覆盖并释放出空间。相反,冷段通常包含了不活跃的数据块,可以尽快清理这些段,以释放空间。这种策略可以根据数据的访问模式来优化垃圾清理的效率,但是需要额外的空间来记录段的热度,可能会影响性能。
3. 基于空闲时间的策略:
LFS 可以通过记录每个数据块的空闲时间来判断哪些块是不活跃的。当一个数据块空闲时间超过一定阈值时,它就可以被清理掉。这种策略可以有效地清理不活跃的数据块,但是需要额外的空间来记录空闲时间,可能会影响性能。
需要注意的是,以上策略并不是互斥的,可以根据具体情况选择合适的策略。同时,LFS 还需要考虑何时清理,如周期性清理、空闲时间清理、磁盘满时清理等。这些策略和清理时间的选择都会影响垃圾清理的效率和性能。
崩溃恢复和日志
最后一个问题:如果系统在LFS写入磁盘时崩溃了会发生什么?也许你还记得上一章讲的日志,在更细期间崩溃对于文件系统来说是棘手的,因此,LFS也必须考虑这些问题。
在正常操作期间,LFS将一些写入缓冲在段中,然后(当段已满或经过一段时间后),将段写入磁盘。为了处理系统崩溃的情况,LFS 采用了日志结构的设计,将所有的写操作都记录在日志中。具体来说,LFS 在日志中组织这些写入,即指向头部段和尾部段的检查点区域,并且每个段指向要写入的下一个段。
LFS 还定期更新检查点区域(CR)。在这些期间都是有可能发生崩溃的(写入段,写入CR),那么LFS在写入这些结构时是如何处理崩溃?
头部段和尾部段是指LFS中的两个特殊段,它们分别位于文件系统的开头和结尾。头部段包含了文件系统的元数据信息,如文件的inode表、imap表、段摘要块等。尾部段则用于记录文件系统的状态信息,如当前正在使用的段号、下一个可用的段号等。在LFS中,每个段都包含了一些数据块,这些数据块可以是文件的内容,也可以是文件系统的元数据信息。当LFS写入数据时,它会将一些数据缓存在一个段中,当这个段已经写满或者经过一段时间后,LFS会将这个段写入磁盘。为了保证数据的一致性和可靠性,LFS会将所有的写操作记录在一个日志中。这个日志中包含了指向头部段和尾部段的检查点区域,以及每个段指向要写入的下一个段的信息。
我们先来介绍一下第二种情况,LFS 定期更新检查点区域(CR)。为了确保CR的更新是原子性的,LFS会保留两个CR,每个位于磁盘的一端,并交替写入它们。为什么需要两个,其中一个是完整的备份。这样做的目的是让 LFS 在更新 CR 时更快地完成。每次更新 CR 时,LFS 都会交替写入 CR1 和 CR2,以便每次更新后的 CR 可能会在下一次更新时成为陈旧的的备份。这种设计有一个好处可以让 LFS 在 CR 更新期间仅保留一个小的副本,因此 CR 可以更新得更频繁(每几秒钟或每分钟一次),从而降低了系统崩溃时因数据损坏而引起的数据丢失的可能性。也就是说,交替写入两个 CR 意味着如果一个 CR 损坏,那么更老的,具有一致时间戳的备份就可以被用来恢复文件系统数据。
LFS 还实现了一个谨慎的协议。具体来说,它首先写出一个头(带有时间 戳),然后写出 CR 的主体,然后最后写出最后一部分(也带有时间戳)。
如果系统在cr更新期间崩溃,LFS 可以通过查看一对不一致的时间戳来检测到这一点。LFS 将始终选择使用 具有一致时间戳的最新 CR,从而实现 CR 的一致更新。
我们现在再来关注一下第一个情况。由于lfs每隔30s左右写入一次cr,因此文件系统的最后一致快照不一定有最新鲜的内容。在系统崩溃重新启动时,lfs会简单地读取检查点,然后以最后的检查点进行恢复。但是,最后的很多秒的更新将会丢失。
为了改进这一点,lfs尝试通过数据库社区称为前滚(roll forward)的技术,重建其中一些段。基本思想是从最后一个检查点区域开始,找到日志的结尾(包含在cr中),然后使用它来读取下一个段,并查看其中是否有任何有效更新。如果有,lfs会相应地更新文件系统,从而恢复自上一个检查点以来写入的大部分数据和元数据。有关详细信息,请参阅rosenblum获奖论文。
“Design and Implementation of the Log-structured File System”Mendel Rosenblum 关于 LFS 的获奖学位论文,包含其他论文中缺失的许多细节。