



内存分割与合并
前面我们已经知道,操作系统会通过空闲列表来管理未被使用的空间,空闲列表会记录未被使用的空间,如一个30字节的堆,中间10字节被使用了


那么这个空闲列表会有两个元素,如下所示

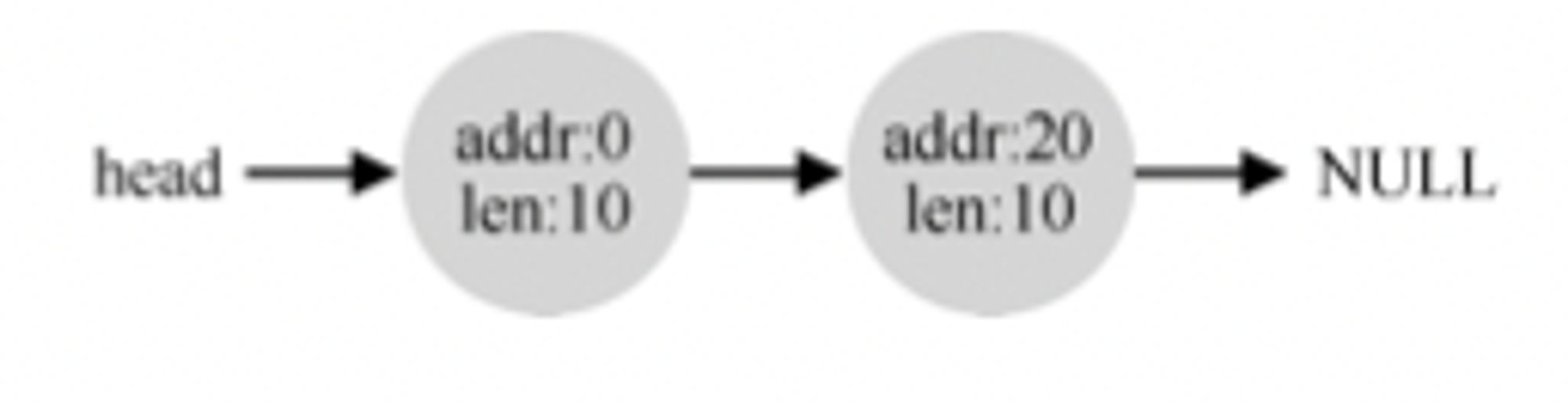
可以看到,这个空闲列表有两个块,因为它是用来记录空闲的空间的。我们一共有20字节的空闲空间,如果此时需要分配15字节大小的空间是分配不出来的,因为没有连续的15字节空间可供分配。
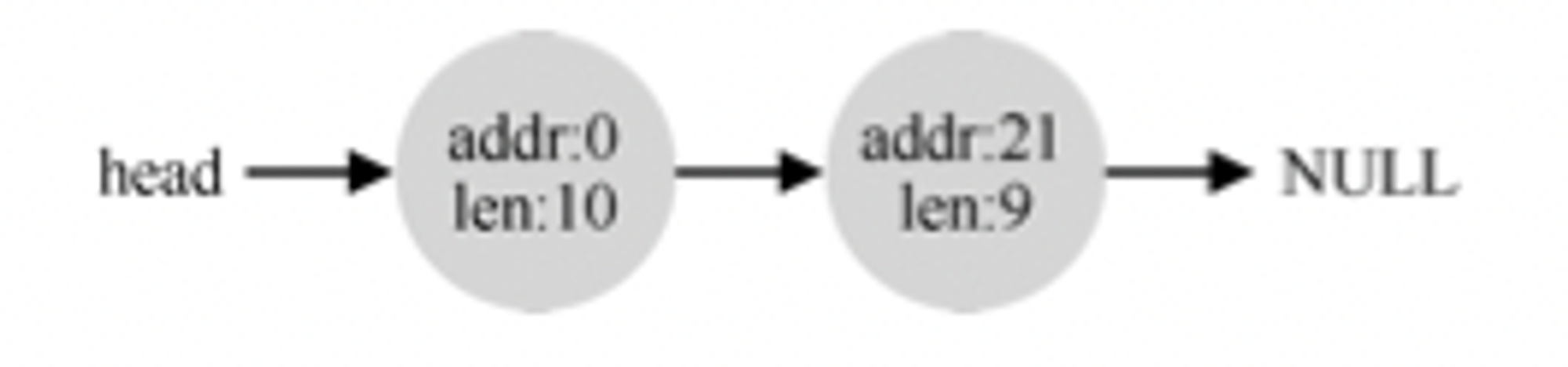
但是如果我们现在需要进行1字节的空间分配,分配程序会执行所谓的分割(splitting),它会找到一块可以满足请求的空闲空间,将其分割,第一块返回给用户,第二块留在空闲列表中。如malloc(1)的调用会返回地址20(1字节分配的区域地址地址),那么空闲链表就会变成下图这样,第二个空闲区域的起始位置从20变成了21。

空闲列表还有对应的合并(coalescing)操作,还是刚刚的的例子,一共30字节,中间10字节被占用了,此时如果调用free()将中间10字节进行释放了,会发生什么?如果只是简单的将其加入到空闲列表,那么就会变成下图这样


很显然这样是有问题的,堆明明没有任何块被使用,但是空闲列表缺将其分割成了3个10字节的块。此时如果用户要求分配20字节的空间,是没办法进行分配的。
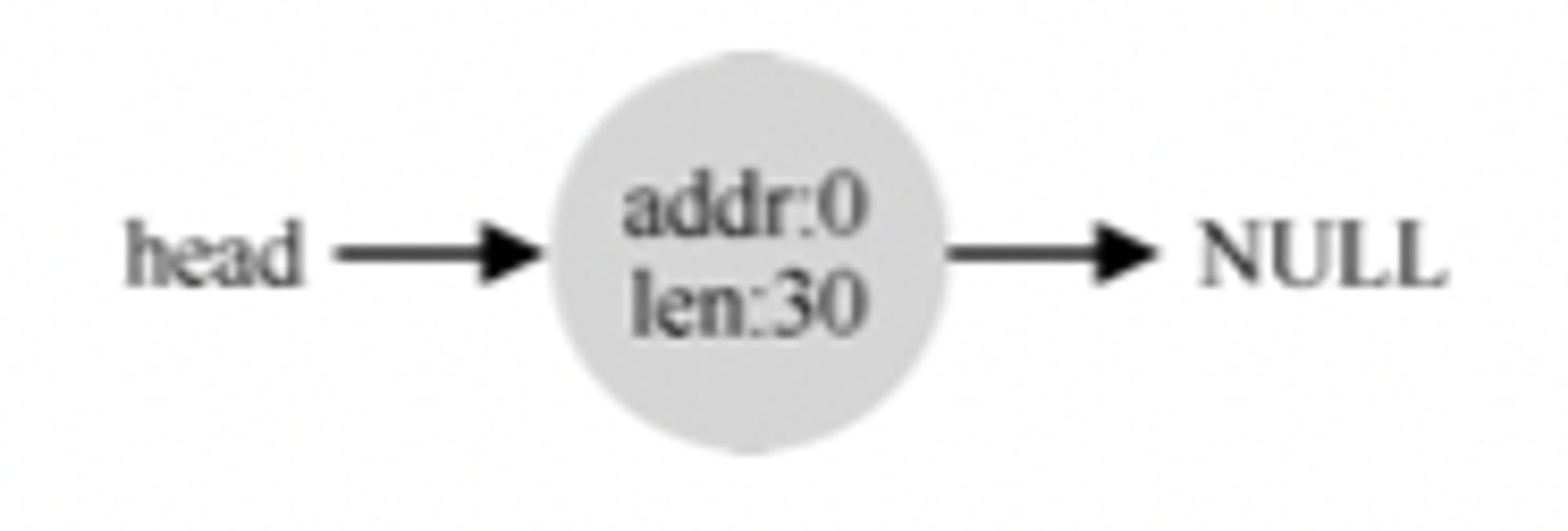
为了避免这个问题,分配程序在给空闲列表添加块的时候会前后查看一下时候也有空闲的块,如果有的话,会将其进行合并,合并后它会向下图这样

追踪已跟踪的块大小
我们现在可以发现使用
free()释放内存时是不需要知道块的大小的,感觉这是很有意思的一件事。那么操作系统是如何知道要释放多少内存的呢?其实分配程序在分配的时候就会将块的一些基本信息保存在头中。头块是一个单独的内存块,每块被使用的空间都会有一个头块来记录这个空间的一些基本信息,其中可能会有使用块的大小,以及一个幻数(C语言中的概念,直接使用的常数就被称为幻数,如 i<16; 这个16就是一个幻数,16代表什么意思需要询问具体的开发人员才知道。在这里 幻数的左右优点类似于令牌(token))
然后调用free()的时候,free内部会做类似如下操作,来得到头块的位置
当拿到头块的指针后,库可以很容易的确定幻数是否符合预期,作为常规性检查(assert(hptr→magic == 1234567)),然后计算要释放的空间大小(即头块的空间加区域长度)

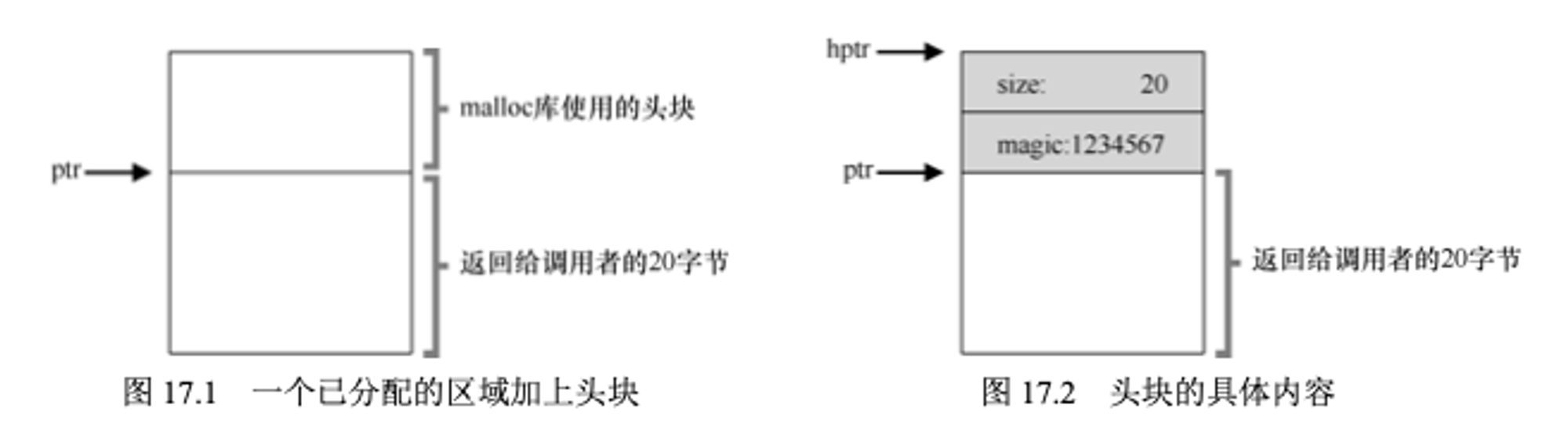
头块
这里需要注意,头块是独立与分配给用户所需大小的内存块,如果用户需要分配大小为N的块,分配程序不是去寻找大小为N的块然后然后进行分配,分配程序需要查找头块+大小为N的空闲块。
释放内存块
现在假设我们需要管理一块4KB(4096)大小的堆,为了将它作为一个空闲列表来管理。首先需要初始化这个列表,这个列表在刚开始的时候只有一个条目,记录了4096大小的空间(需要减去头块的大小,假设头块大小需要8字节,4字节用来记录大小,4字节用来记录幻数),下面是这个空闲列表节点的结构描述
接下来我们可以开始初始化堆了,通过系统调用
mmap()来初始化构建,这只是其中一种初始化方法这段代码执行完成后,空闲列表现在就有一条条目了,它的大小是4088(因为减去了头块),head指针指向了这块区域的起始位置,假设这个位置是处于虚拟地址
16KB的位置。同malloc函数申请内存空间类似的,mmap建立的映射区在使用结束后也应调用类似free的函数来释放。
参数 | 描述 |
start | 映射到进程空间的起始地址,内核指定,直接传递NULL |
len | 映射空间字节数,从offset算起 |
prot | 共享内存的访问权限(PROT_READ可读,PROT_WRITE可写,PROT_EXEC可执行,PROT_NONE不可访问) |
flags | MAP_FIXED 如果参数start所指的地址无法成功建立映射时,则放弃映射,不对地址做修正。通常不鼓励用此旗标。
MAP_SHARED 对映射区域的写入数据会复制回文件内,而且允许其他映射该文件的进程共享。
MAP_PRIVATE 对映射区域的写入操作会产生一个映射文件的复制,即私人的“写入时复制”(copy on write)对此区域作的任何修改都不会写回原来的文件内容。
MAP_ANONYMOUS 建立匿名映射。此时会忽略参数fd,不涉及文件,而且映射区域无法和其他进程共享。
MAP_DENYWRITE 只允许对映射区域的写入操作,其他对文件直接写入的操作将会被拒绝。
MAP_LOCKED 将映射区域锁定住,这表示该区域不会被置换(swap) |
offset | 默认0,从文件头开始映射 |
现在假设有一个100字节的内存请求,库首先会先找到一个足够的块,很显然现在只有一个4088的块,之前我们学习过,库会对这个空闲块进行分割(split),然后把对应大小的块返回给用户,其它的继续作为空闲块。

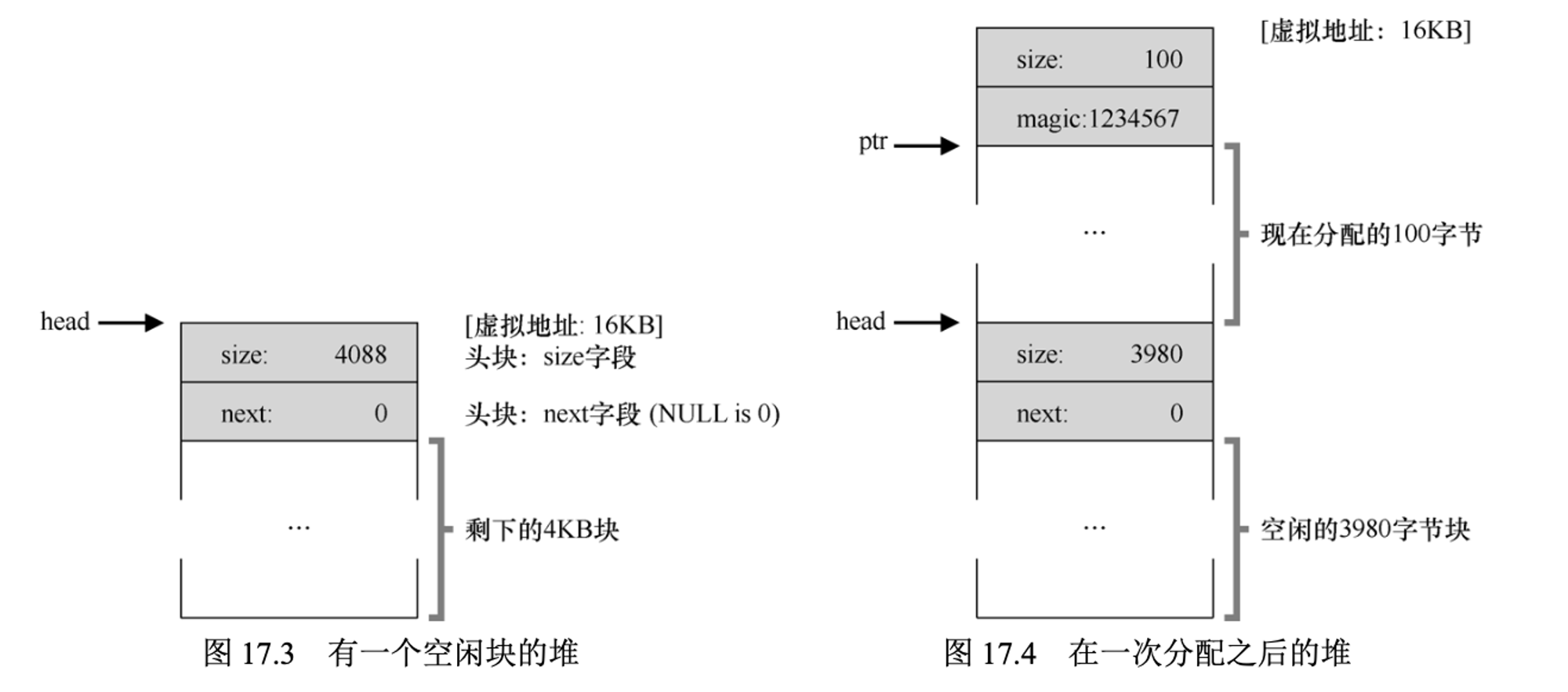
分配完成后的堆如上图右侧所示,4088的块减去了108(100+头块8字节)的大小,同时将返回一个指向它的指针(上图中ptr表示),供未来的free使用,现在块只剩下3980大小。
紧接着,现在又来了两次100字节的内存分配,那么现在堆会如下图所示,一共有3个100字节的块被使用了。

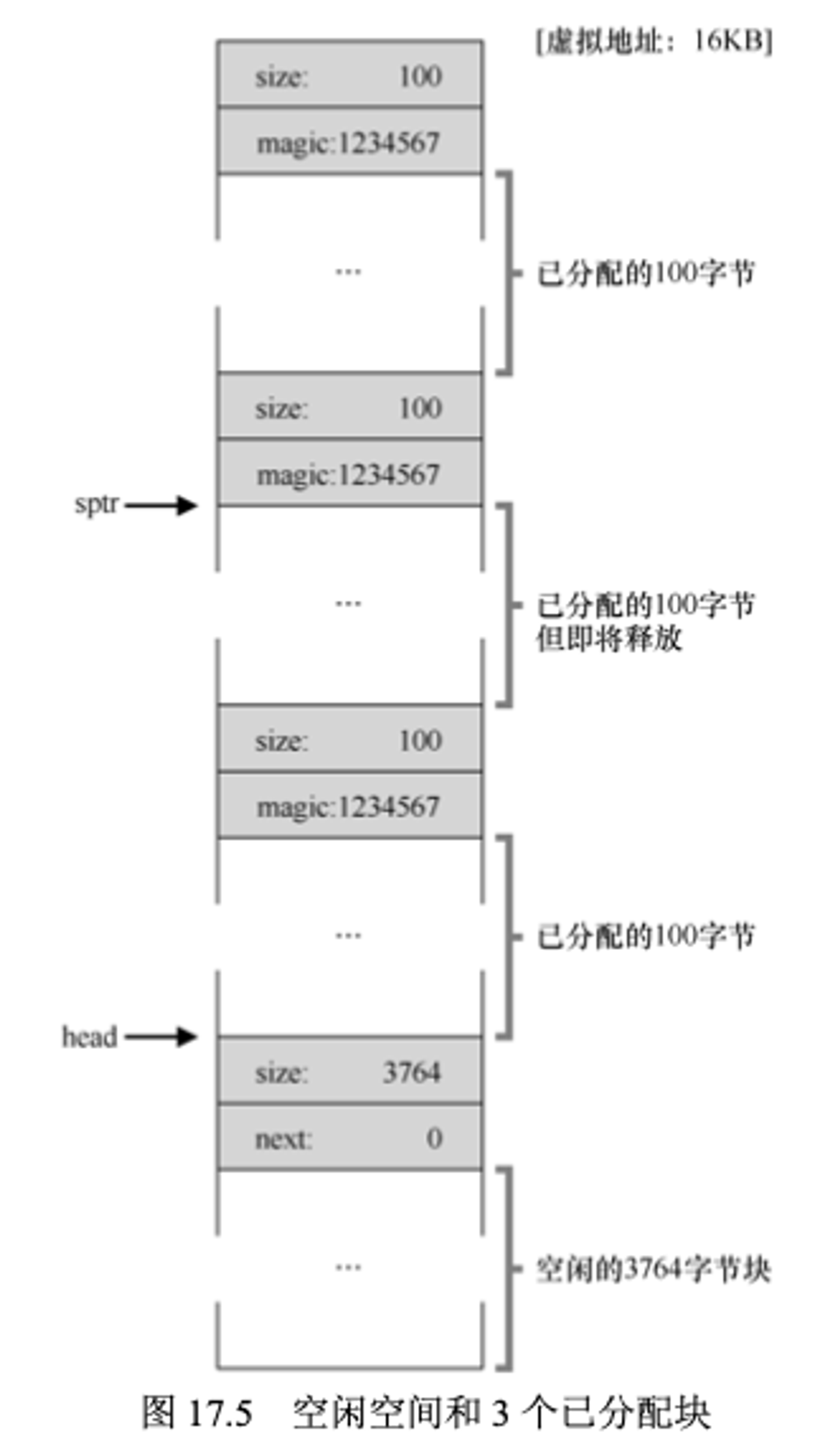
现在堆只剩下3764字节大小,此时假设应用程序调用了 free(16500), 归还了中间的一块已分配的空间(内存起始位置16KB 16384+前108+这一块的头块8字节,得到16500),此时堆会发生什么呢,如下图所示

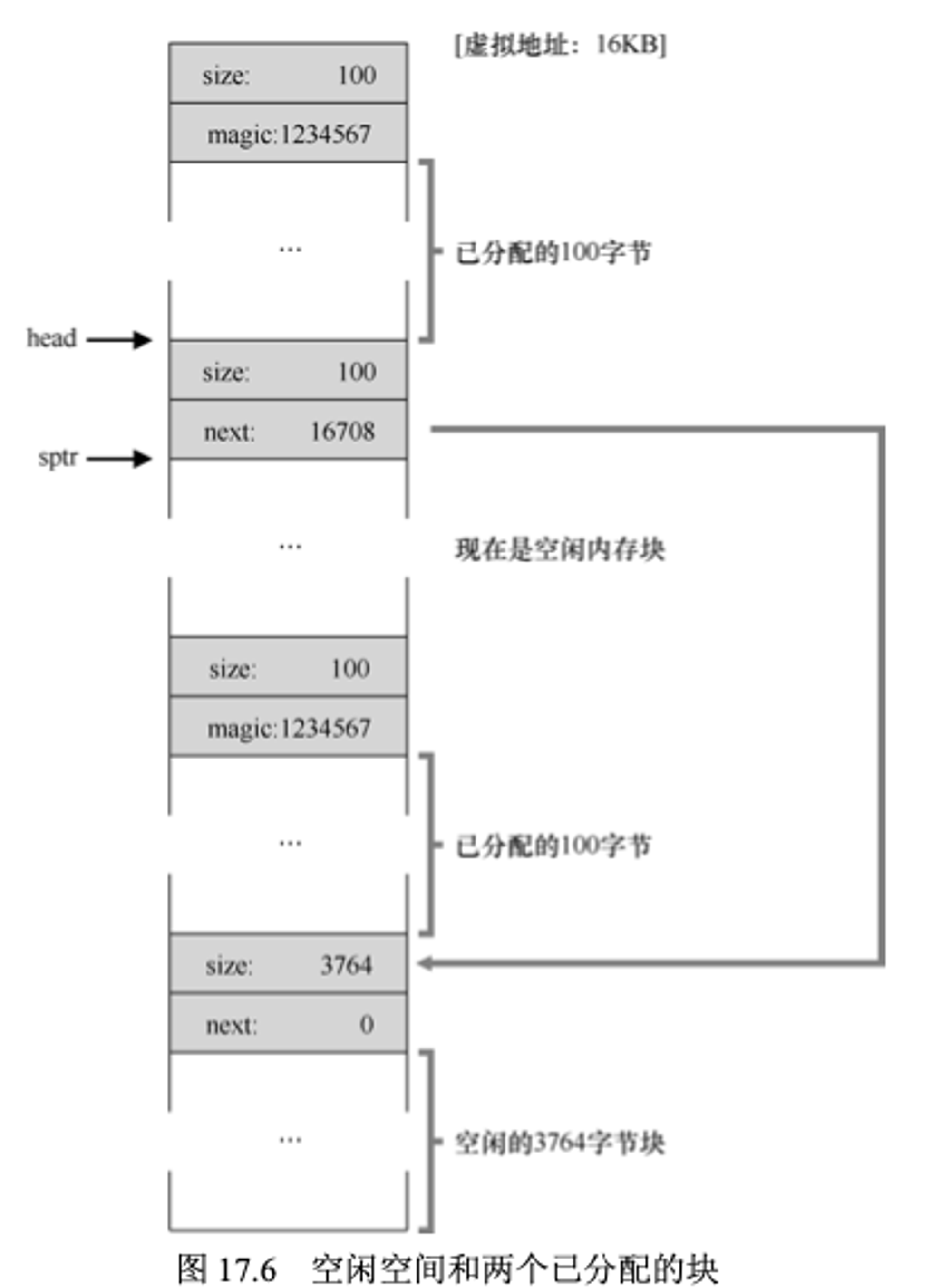
此时空闲列表就会是两个条目了,其中一个较小的空闲块(即刚被释放的100字节)和一个较大的空闲块(3764字节)
假设现在另外两块内存块也被释放了,那么现在堆会是怎样的场景了,如果库没有将这些空闲块进行合并,那很显然,空闲列表现在会有多个空闲块,如下图所示

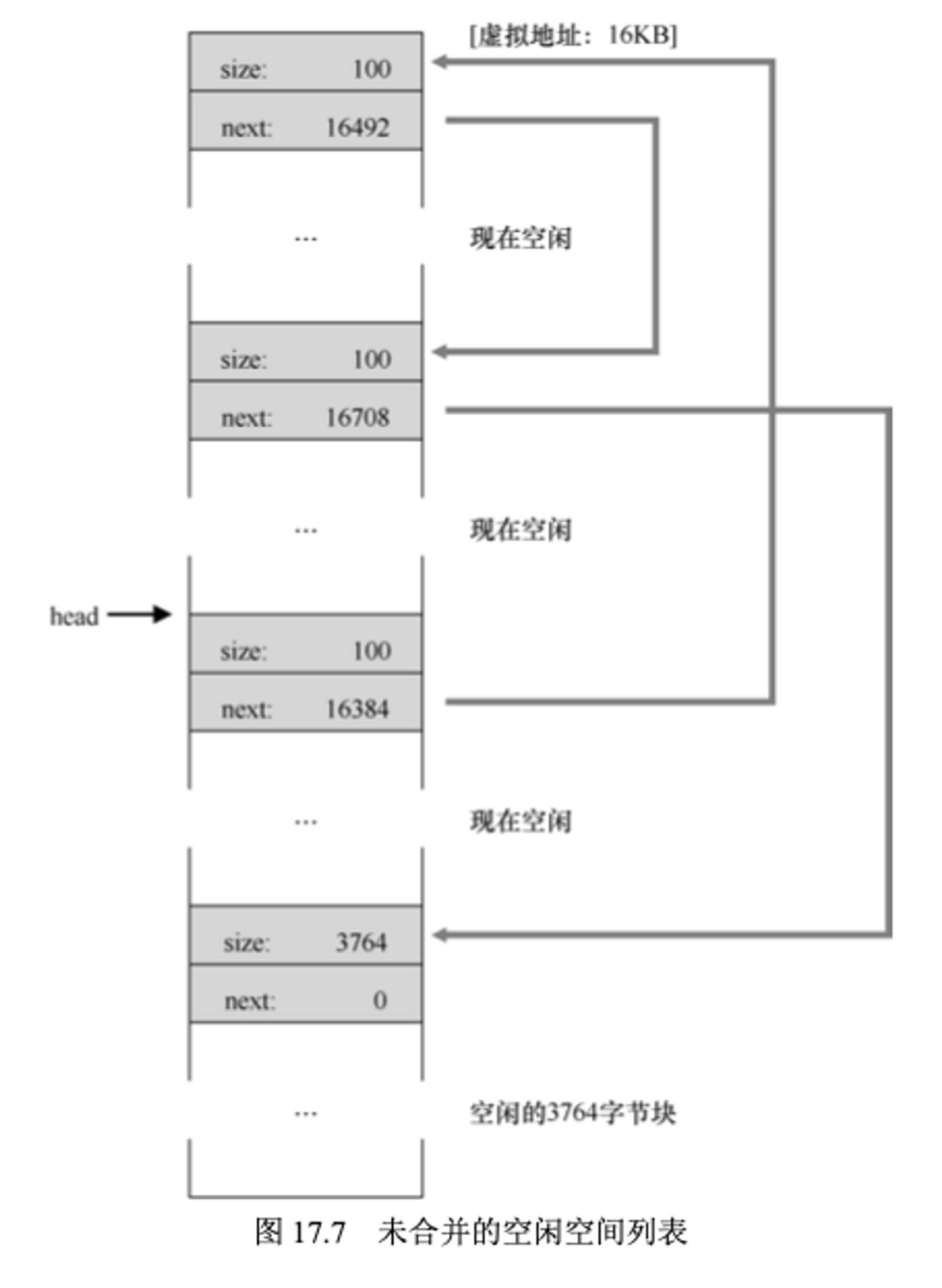
这样就形成了碎片化的内存空间。要解决这个问题只需要遍历这个空闲列表,然后将相邻的两个空闲块进行合并(merge)即可,合并完成后,这个堆又形成了一个整体。
让堆增长
brk和sbrk
brk和sbrk是unix系统中用来调整内存大小的两个系统,它们都是用来改变程序分断(break)的位置,堆结束的位置。
两者的区别是brk的参数是通过传入新的结束地址(新分断的地址)来调整,sbrk是通过一个可以为负数的参数来进行调整,在最早的unix系统中,这俩是唯一可以申请更大内存空间的方式,现在一般不会直接去使用这俩来申请内存空间,会使用进一步封装的malloc或者mmap等来代替
sbrk函数如果传入0则会返回程序当前的中断地址
man手册中也可以查询到这俩个系统调用api的文档
参考链接
管理空闲列表基本策略
这里不讨论哪种策略是”最好”的,我们知道,如果有一千种解决方案,那就没有最好的。这里只学习一下书上列举的这些策略,当然还有更多其它的。
最优匹配(best fit, 最小匹配)
最优匹配需要进行一次完整的空闲列表遍历,然后找到最合适的大小,将其返回。这个策略可能会导致很多无法继续的小空闲块。
最差匹配(worst fit)
最差匹配需要进行一次完整的空闲列表遍历,然后找出最大的空闲块,将其进行分割(split)。大多数研究表明这个策略的性能很差,会造成很多内存碎片。
首次匹配(first fit)
首次匹配不需要遍历完空闲列表,从head开始遍历,当找到第一个足够大小的空闲块时,就会将其进行分割,然后将对应的空间返回。这个算法可能会对列表的头部造成多次分割,使其头部生成大量的内存碎片。
下次匹配(next fit)
下次匹配是在首次匹配的基础上,多维护了一个指针,这个指针会记录上一次遍历的位置,使得空闲列表的遍历能够分散到整个堆去,而不是一直在列表的头部进行切割。这个策略的性能和首次匹配很接近,同样不需要完整的遍历空闲列表。
分离空闲列表
有一种很有趣的方案叫做分离空闲列表(segregated list),这个想法是,如果某个应用频繁对一种(或多种)同一类型的内存空间进行申请和释放,那就用一个单独的空闲列表来进行管理,而其它大小的内存分配都交给更通用的内存分配程序。
这种方式可以避免碎片化的问题,因为每次都是申请特定的大小,而这个空闲列表早就准备好了这些合适的块进行分配,在分配的和释放都可以很高效
但显然,这个前提是需要预先准备好一部分内存空间用来单独管理,那么拿出多少空间来进行管理也就变成了一个很值得考究的问题。
Sun公司的研究员Jeff Bonwick为Solaris系统内核设计的slab allocator分配程序是比较出名的一个程序,这个程序很优雅的解决了这个问题。
它的主要思想是在内核通过预先分配好一系列空闲列表以供使用,同时给每个块通过引用计数的方式来标记是否被使用,所以对于这个分配程序来说,进行分配和释放的速度都是恒定的。
注:Jeff Bonwick是一个很厉害的工程师,同时是文件系统ZFS的负责人,硅谷的灵魂。
但这个方式依旧会有少量的内部碎片(即每一个小块的空间的内部可能有一小部分是一直没有被使用的),slab allocator是一个很值得学习的一个分配算法思想,著名的memcached的分配算法也是用的这个算法,有关这个算法可以单独记一篇笔记
伙伴系统
还有一种算法叫做伙伴系统,这种算法在对空闲列表的合并更简单。这个算法的想法也很简单,首先它会将空闲空间视为一个的大空间,当对内存分配时没有合适内存时,会对这个空间递归的一分为二,直到刚好的满足所需的大小。如下图的例子,需要分配一个7KB的空间。

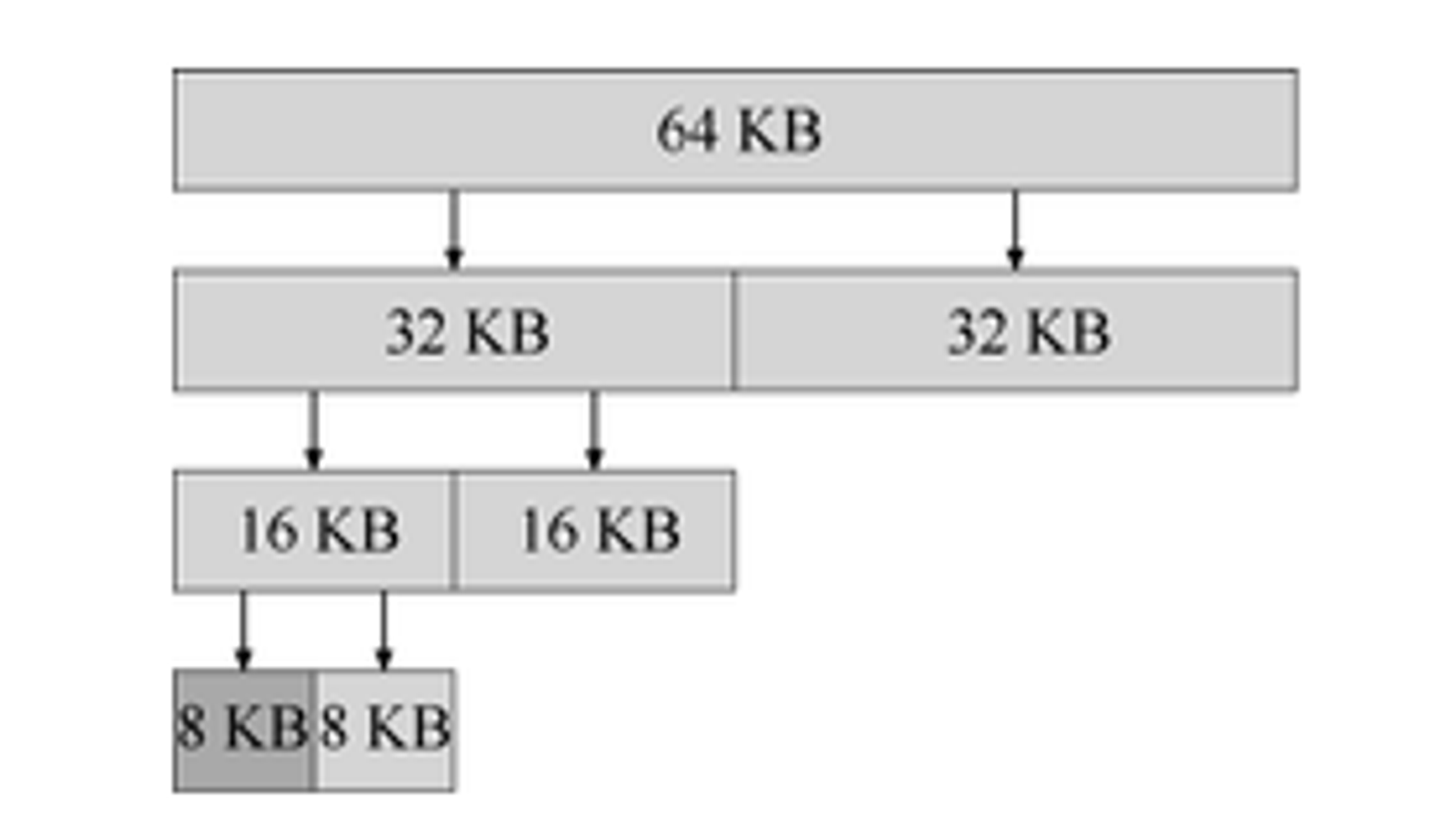
这个算法只能切割出的整数次幂大小的块,因此会有内部碎片(internal fragment)。
当要对这个空间进行释放的时候,这个算法的优势就体现出来了,它会去看它的伙伴是否也是空闲的,如果它的伙伴也是空闲块,那么它俩就会进行合并,然后依次向上递归进行合并,直到发现伙伴是被使用的才停止。确认伙伴是谁也很简单,它们之间只有第一位不同。
如下
ㅤ | a | b | c | d |
起始地址 | 0 | 4096 | 6144 | 8192 |
空间范围 | 0 ~ 2047 | 4096 ~ 6143 | 6144 ~ 8191 | 8192 ~ 10239 |
二进制地址 | ㅤ | 0x1000000000000 | 0x1100000000000 | 0x10000000000000 |