



起因
根据前面已学的知识,我们知道,如果在一个32位的地址空间,4KB的页和4KB的页表项,那么这个系统就会有一百万个页表项( = 4294967296, 4294967296/4096=1048576),再乘以页表项的大小(4字节)可以得到大小是
4MB(1048576 * 4 = 4194304),也就是说,一个进程就需要4MB大小的页表,如果这个系统上现在运行了100个进程(现代操作系统很常见)的话,光给页表就需要分配上百兆的内存。更小的页表
一种解决方案是减小页表的大小,而使用更大的页(即每页会变得更大)。如32位的地址空间为例,现在使用
16KB的页。因此会有18位的VPN和14位的偏移量(),假设每个页表项(4字节)大小相同,那么现在页表只需要1MB就足够了/ 16KB = 262144, 262144 * 4 = 1048576, 1048576 = 1024KB = 1MB , 对比原来的4MB大小页表,缩小到了四分之一。多种页大小 目前我们提到的都是假设页大小是相同的,如都是4KB或者8KB,但是,其实很多体系架构(MIPS, SPARC, x86-64)都支持多种页大小,可以给地址空间的指定部分使用一个大型页(如4MB),这样应用程序可以将一些比较常用的大型数据结构放入这样的空间。 在TLB中,这个映射也只会占用一项,这种大页在数据库管理系统和其它高端商业应用程序中很常见。 需要注意,多页大小主要不是为了节省页表空间,它主要是为了减轻TLB的压力,尽可能的让TLB命中。 显而易见的是,如果采用这种多页大小,会让操作系统的内存分配程序更复杂。所以,有时候只需要向应用程序提供一些接口,直接让应用程序去请求大的内存页,这样会简单许多
但是,如果把页的size变大的话, 同时会导致新的问题,因为大分页很容易导致内部碎片(internal fragmentation),应用程序可能只使用了很小一部分空间,但是需要给它分配一个完整的页,这可能会导致内存的浪费,如果系统运行的够久的话,可能内存会充满这些页。所以其实很多系统的都是采用较小的页:如4KB(x86)或8KB(SPARCv9)。
分页和分段
在生活,如果两种方案都可以,但是都有些弊端,我们会思考,能不能让这两种方案进行结合。就和之前很流行的梗一样,小孩子才做选择题,我全都要。在计算机领域,我们把这种称为杂合(hybrid)。
Multics 的创造者(特别是 Jack Dennis)在多年前构建 Multics 虚拟内存系统时,偶然发现了这样的想法。他想到了让分段和分页想结合,以减少页表的开销。
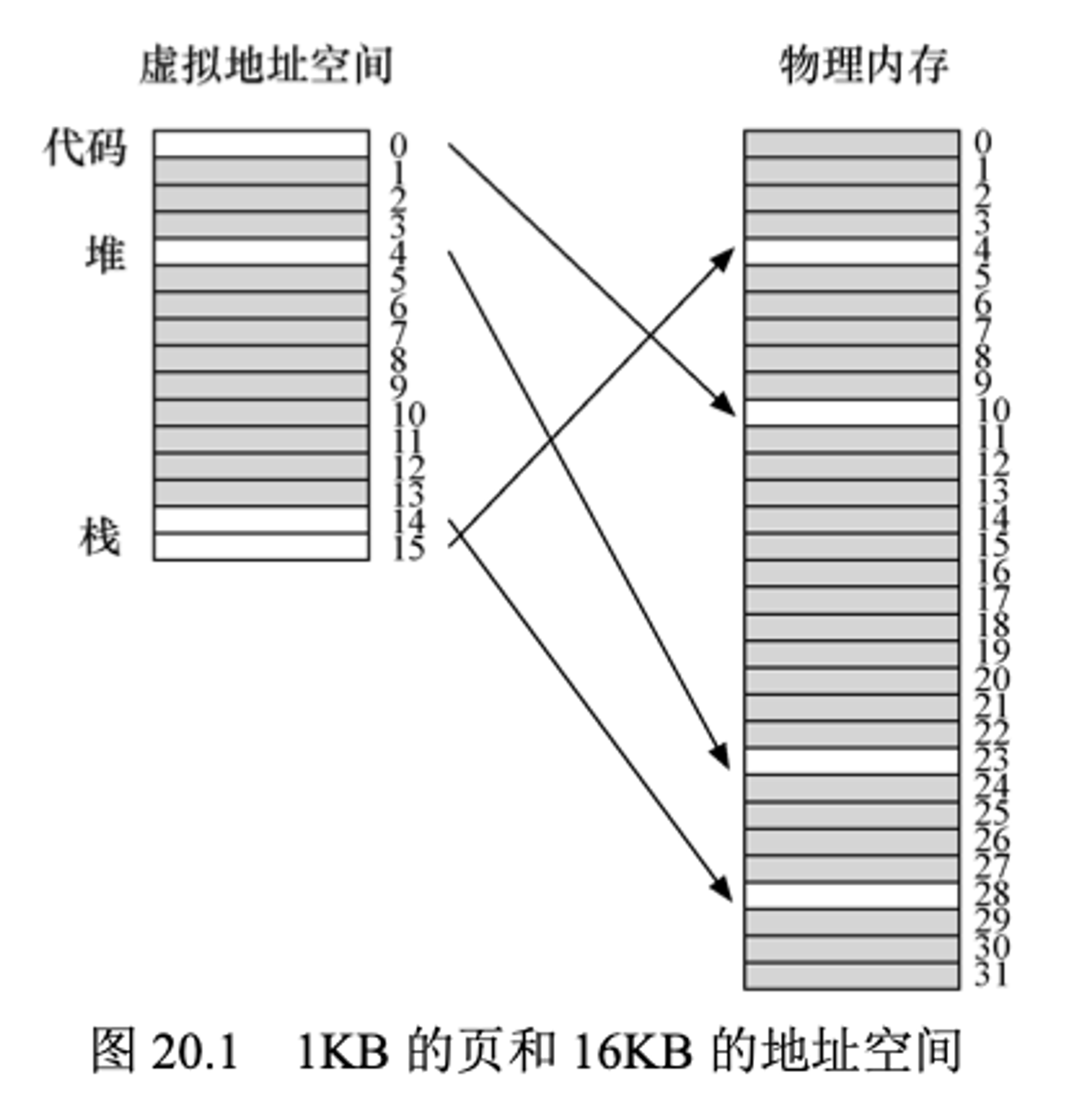
通过一个简单的示例,可以更好的理解为什么要这么做。假设我们有一个堆和栈使用量都很小的一个地址空间。假设这个地址空间是
16KB,每页是1KB,如下图所示
在上图中,
VPN 0映射到了物理页10,VPN 4映射到了物理页23,以及地址空间的另一端(VPN 14和15)被分别映射到了28和4。从上图中可以看到,有很多区域是没有使用的(灰色块),充满了无效(invalid)项,但是它依旧占用了实际的内存,这很浪费。只是一个很小的
16KB例子就这样,如果是32位的地址空间可能会浪费更多的地址空间。如下是一个线性页表。PFN | valid | prot | present | dirty |
10 | 1 | r-x | 1 | 0 |
- | 0 | - | - | - |
- | 0 | - | - | - |
23 | 1 | rw- | 1 | 1 |
- | 0 | - | - | - |
- | 0 | - | - | - |
- | 0 | - | - | - |
- | 0 | - | - | - |
- | 0 | - | - | - |
- | 0 | - | - | - |
- | 0 | - | - | - |
- | 0 | - | - | - |
- | 0 | - | - | - |
28 | 1 | rw- | 1 | 1 |
4 | 1 | rw- | 1 | 1 |
如果我们采用杂合的方案的话,就不再是原来那样,给进程提供单个页表了,而是会给虚拟地址分段,然后给每个段提供一个页表,同时每个段都有自己的基址(base)寄存器和界限(bound)限制(limit)器,通过这对寄存器来知道段的大小。
在杂合方案中,我们在MMU中依旧拥有这些结构。这里的基址寄存器指向的是页表的地址,界限寄存器指向的是页表的结尾(即拥有多少有效页)。
我们依旧通过一个简单的例子来理解,假设我们有一个32位的地址空间,它每页的大小是4KB,同时地址空间被分成4个段。但是在这个例子中我们只使用3个段:代码段,堆段,栈段。
当我们发起一个地址访问的时候,通过地址的前2位来来判断引用的是哪个段。假设00是未使用的段,01是代码段,10是堆段,11是栈段,因此虚拟地址空间如下所示


那么在硬件中需要有3个基本/界限对,分别给代码,堆,栈段来使用,代码运行时,每个段的寄存器都记录着这个段的线性页表地址。也就意味着每个进程都有3个和它关联的页表。在上下文切换时,需要更改这些对应的寄存器,以更新进程的页表位置。
当TLB未命中时(假设硬件管理TLB,即硬件处理TLB未命中),硬件使用分段位(SN)来确定要使用哪个基址和界限对,然后硬件将物理基址和
VPN结合起来,拿到新的页表项(PTE)杂合方案的关键在于,当代码段只使用了前3个页(0,1,2页),那么代码段将只有3个项被使用,同时界限寄存器会被设置为3,如果访问超出的话就会抛出一个异常。这种方式比传统的线性页表,杂合方案实现了显著的内存节省。栈和堆之间未分配的页不会占用页表的空间(将其标记为无效)。
但其实杂合依旧没有解决问题。
- 首先它需要使用分段,分段会导致不太灵活,因为它假定地址空间有一定的使用模式。如一个大而稀疏的堆,依旧可能会导致严重的页表浪费。
- 另一方面,这种杂合方案依旧会导致外部碎片的再次出现。尽管大部分内存是以页表大小单位管理的,但页表现在可以是任意大小(PTE的倍数)。因此,在内存中为它们寻找自由空间更为复杂。
出于这些原因,我们需要寻找更好的方式来实现更小的页表
提示: 使用杂合
当你有两个看似相反的好主意时,你应该总是看到你是否可以将它们组合成一个能够实现两全其美的杂合体(hybrid)。
例如,杂交玉米物种已知比任何天然存在的物种更强壮。当然,并非所有的杂合都是好主意,请参阅 Zeedonk(或 Zonkey),它是斑马和驴的杂交。如果你不相信这样的生物存在,就查一下,你会大吃一惊。
多级页表
还有一种方案不需要使用分段,它也是用来解决同样的问题:如何去掉页表中所有的无效区域,不将它们都保存在内存中。我们将这种方案称为多级页表(multi-level page table),它将线性页表变成了类似树的结构,很多现代系统(如x86)都使用它。
它的思想很简单,它有一个叫页目录(page directory)的结构,这个页目录的将每个单元对应一个二级页表,如果二级页表整页的页表项(PTE)都无效,就完全不分配该页的页表。这个页目录的结构会记录页表的内存地址。
如下图是一个简单的例子,图左边是一个经典的线性页表。尽管中间有很多区域没有使用的,但是我们仍然要给这些区域分配内存。右侧是一个多级页表,页表仅将两项标记为有效(第一个和最后一个);因此,页表中只有这两页会驻留在内存中。多级页表是让线性页表的一部分消失(释放这些物理帧给其它用)

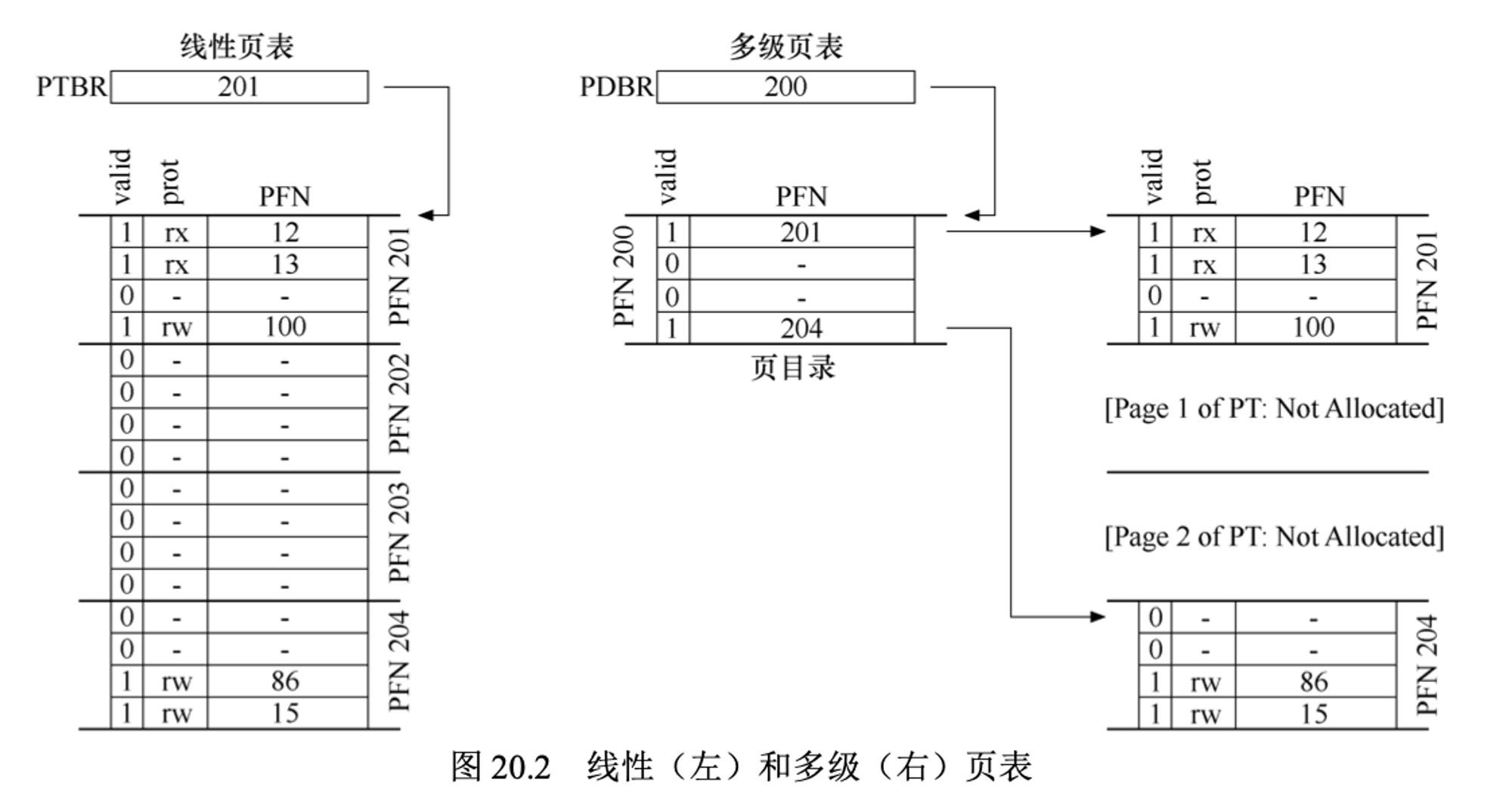
在一个简单的两级页表中,页目录中的每一项都包含了一个二级页表。它由多个页目录项(Page Directory Entries, PDE)组成。PDE至少拥有有效位(valid bit)和页帧号(page frame number, PFN)类似与PTE。
但是页目录中的有效位会有些不同:如果PDE项是有效的,则表示该项指向的页表(通过PFN)中至少一页是有效的,即在该PDE所指向的页中,至少有一个PTE,其有效位被设置为1。
多级页表有很多明显的优势。
- 多级页表分配的空间,与正在使用的地址空间内存量成比例。它通常很紧凑,并且支持稀疏的地址空间。
- 如果更仔细的构建,页表的每个部分都可以整齐的放入一页中,从而更容易管理内存。
操作系统可以在需要分配或者增长页表时简单地获取下一个空闲页。对于普通的线性页表而言,线性页表是按VPN索引PTE的数组。这样的结构需要整个页表都在驻留在内存中。对于一个大的页表(4MB),在这个页表中,如果要寻找一块大块的,未使用的连续物理内存,可能是一个相当大的挑战。
但是采用多级结构,通过增加了一个间接层(level of indirection)页目录,它指向页表的各个部分。这种间接的方式,我们可以将页表放在屋里内存的任何地方。
理解时空折中
在构建数据结构时,始终都应该考虑时空折中(time-space trade-off)。如果你希望更快的访问特定的数据结构,那么就必须为这个空间付出代价。
但是多级页表也不是没有任何缺点的。
- 在TLB未命中时,需要从内存中加载两次(第一次加载页目录,第二次加载对应的页表),如果是线性页表只需要加载一次。因此,多级页表是一个时空折中是一个小例子,我们想要更小的页表,在常见情况下性能是相同的,尽管在TLB未命中时开销会更大一些。
- 复杂性提高了,无论是硬件还是操作系统来处理页表都比简单的线性页表查找更复杂,但是通常我们愿意增加复杂性,以提高性能或降低管理费用,在多级页表的情况下,为了节省宝贵的内存,我们使用页表查找更加复杂。
提示:对复杂性表示怀疑
系统设计者应该谨慎对待让系统增加复杂性。好的系统构建者所做的就是: 实现最小复杂性的系统, 来完成手上的任务。
例如,如果磁盘空间非常大,则不应该设计一个尽可能少使用字节的文件系统。同样,如果处理器速度很快,建议在操作系统中编写一个干净、易于理解的模块,而不是 CPU 优化的、 手写汇编的代码。
注意过早优化的代码或其他形式的不必要的复杂性。这些方法会让系统难以理解、维护和调试。
正如 Antoine de Saint-Exupery 的名言: “完美非无可增,乃不可减”。他没有写的是: “谈论完美易,真正实现难”。
详细的多级示例
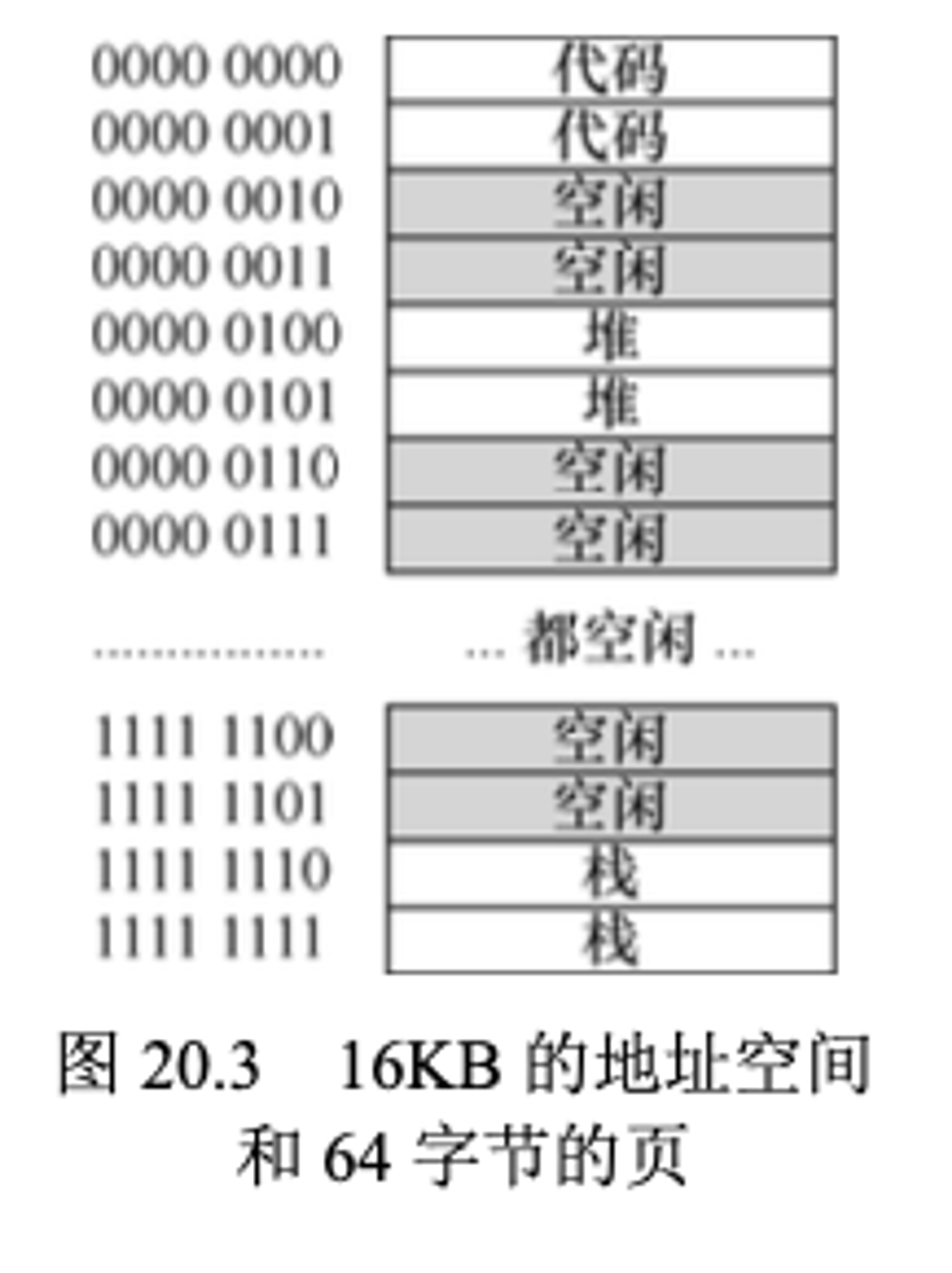
我们来看一个简单的例子,以便更好的理解多级页表。设想一个大小为
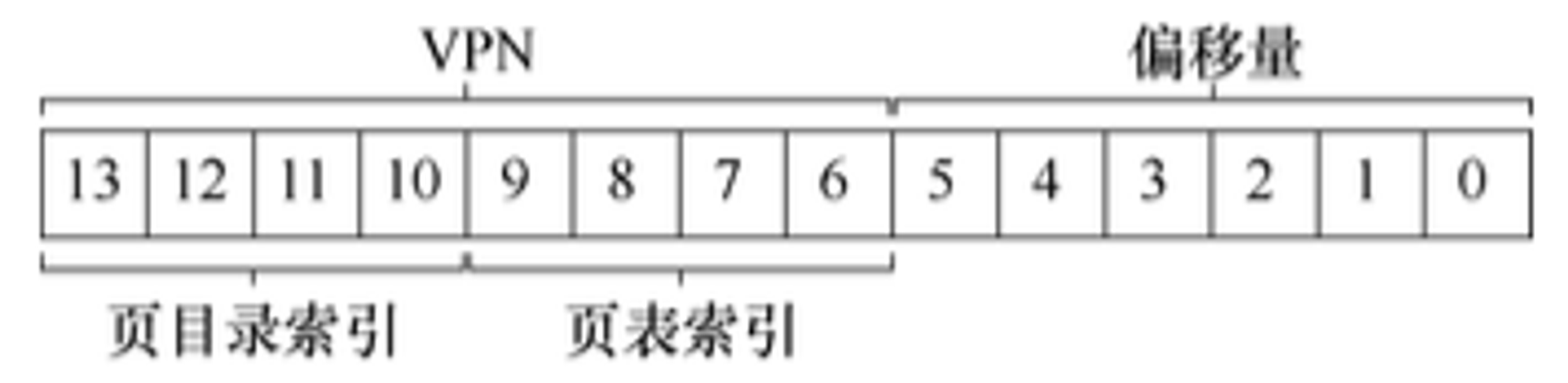
16KB的小地址空间,每个物理页有64字节,也就意味着一共有256个物理页16KB / 64b = 256)。因此,VPN是8位(=256),偏移量是6位()。如果是线性页表的话,即使只有一小部分地址空间只使用,线性页表也会有256项(因为是16KB的地址空间)。如下图所示

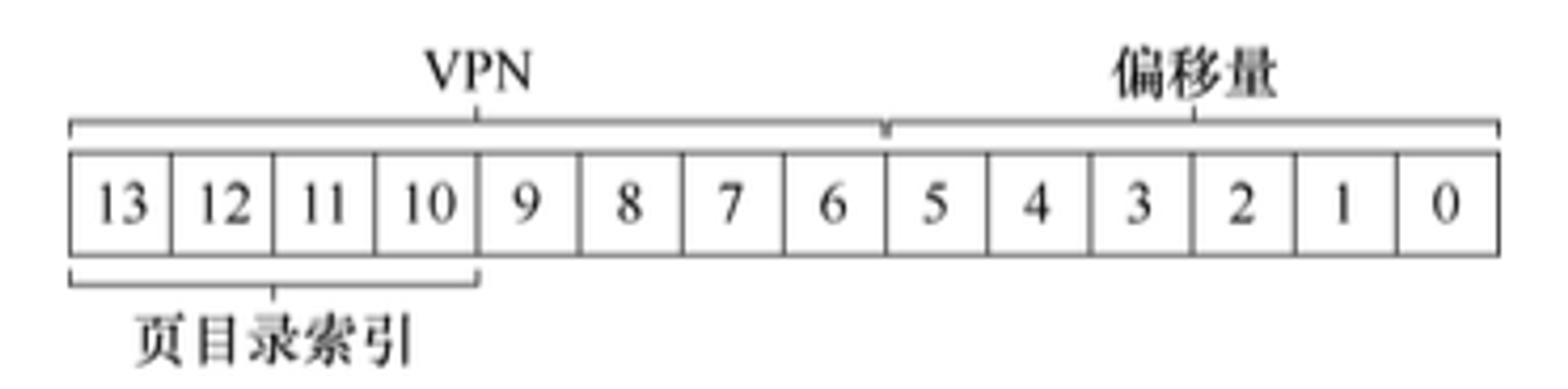
如果要为这个地址空间构建出一个二级页表,在这里我们的完整页表(在我们的例子中)拥有256个页表项(PTE),假设每个PTE是
4字节大小,因此一个页表大小是1KB(),由于我们的物理帧(PFN)大小是64字节,也就意味着,一个页表可以容纳16个物理帧()那么现在如何来获取VPN呢,首先它需要先索引到一级页表(页目录中),然后再索引到二级页表(页表)。我们这个例子的页表比较小:只有256项,这256项分布在16个物理页上。那么页目录就会为每个页提供一项,所以页目录会有16项。因此,我们需要4位()VPN来索引目录,我们使用VPN的前4位,如下图所示

我们拿到了页目录索引(简称 PDIndex)后,再通过简单的计算就可以得到页目录项的地址了:
PDEAddr = PageDirBase + (PDIndex * sizeof(PDE))。这样就得到了页目录的物理地址。接着硬件或操作系统会进行一些检查,检查有效位是否有效,如果被标记为无效,则会抛出异常。如果有效的话,我们需要继续往下做,我们需要从这个页目录所指向的页表中获取出所需的页表项(PTE)。要找到这个PTE,我们需要用到剩余的VPN位来索引到页表

这个
页表索引(Page-Table Index, PTIndex)是用来在二级页表中索引所在项的,通过它可以直接获取到页表项的内容。它的代码如下这里需要注意,首先页目录的页帧号需要必须先左移到位(这个页帧号就是二级页表的地址),然后再拼接上页表索引(在二级页表中的索引),就拿到了PTE。
页目录原本可能是类似1000的地址,左移后可能是100000,然后再拼接上VPN后4位。 它左移的原因就是为了能够正确的定位到二级页表的起始地址,如果不左移,而直接拼接VPN的后4位的话,得出的地址可能错误的
下面有一个包含实际值的多级页表,并转换一个虚拟地址的例子。左侧是页目录,这个表中可以看到地址空间有两个有效区域(在开始和结束处),中间的都是一些无效映射。
在一级页表的第0页,物理页100的为位置,我们有一个二级页表,这个二级页表有16项,纪录了地址空间前16个VPN。在中间的表格有内容体现
Page Directory
PFN | valid |
100 | 1 |
ㅤ | 0 |
ㅤ | 0 |
ㅤ | 0 |
ㅤ | 0 |
ㅤ | 0 |
ㅤ | 0 |
ㅤ | 0 |
ㅤ | 0 |
ㅤ | 0 |
ㅤ | 0 |
ㅤ | 0 |
ㅤ | 0 |
ㅤ | 0 |
ㅤ | 0 |
101 | 1 |
Page of PT(@PFN:100)
PFN | valid | prot |
10 | 1 | r-x |
23 | 1 | r-x |
ㅤ | 0 | ㅤ |
ㅤ | 0 | ㅤ |
80 | 1 | rw- |
59 | 1 | rw- |
ㅤ | 0 | ㅤ |
ㅤ | 0 | ㅤ |
ㅤ | 0 | ㅤ |
ㅤ | 0 | ㅤ |
ㅤ | 0 | ㅤ |
ㅤ | 0 | ㅤ |
ㅤ | 0 | ㅤ |
ㅤ | 0 | ㅤ |
ㅤ | 0 | ㅤ |
ㅤ | 0 | ㅤ |
Page of PT(@PFN:101)
PFN | valid | prot |
ㅤ | 0 | ㅤ |
ㅤ | 0 | ㅤ |
ㅤ | 0 | ㅤ |
ㅤ | 0 | ㅤ |
ㅤ | 0 | ㅤ |
ㅤ | 0 | ㅤ |
ㅤ | 0 | ㅤ |
ㅤ | 0 | ㅤ |
ㅤ | 0 | ㅤ |
ㅤ | 0 | ㅤ |
ㅤ | 0 | ㅤ |
ㅤ | 0 | ㅤ |
ㅤ | 0 | ㅤ |
ㅤ | 0 | ㅤ |
55 | 1 | rw- |
45 | 1 | rw- |
在这个二级页表中,VPN 0 和 1 是有效的(代码段),VPN 4和5(堆)也是。除此之外其它所有都标记为无效。
目录表的另一个有效页在
PFN 101中,这个页表记录了地址空间的最后16个VPN映射。在上表右侧。在上述这个例子中只有
VPN 254和255包含有效映射,从这个例子中已经可以看出多级页表可以节省空间了,如果是一个线性页表的话,需要分配完整的16页,而多级页表只用了3页。这在32位或者64位的地址空间上显然会节省更多。再练习一下地址转换,能理解这个就基本懂了多级页表。这里有一个地址
0x3F80,二进制形式是11 1111 1000 0000,回想一下,我们会用VPN的前4位用来索引目录。因此1111会索引到页目录的第15项(最后一个,1111转成10进制是15)。它指向了物理地址101的页表。接着再用VPN的下4位来索引二级页表从而得到PTE,
1110会索引到第14项(倒数第二个),从而得到物理页55,然后再用物理页拼接上偏移量,得到具体的物理地址,55转出2进制是11 0111,左移后再加上偏移量得到00 1101 1100 0000,大致的计算公式:超过两级
上述我们都假定多级页表只有两个级别:一个页目录表和几页页表。但是在有些情况下,两级页表可能依旧无法满足情况。
通过一个简单的例子来理解为什么两级可能不够用。假设我们有一个
30位的虚拟地址空间,每个虚拟页大小是512字节( = 1073741824,1073741824/1024/512=2048页)。因此VPN是21位(),偏移量是9位()。之前我们设计多级页表是希望页目录表的每一项都能够放下一页。但是如果页目录表太大该怎么办?
要确定多级页表一共需要几级才能让页表中的每一项都能放下一页,首先要确定一页可以放下多少个页表项。鉴于页大小是
512字节,并且假设PTE大小是4字节,那么在一个物理页上,可以存放128个PTE(512/4=128),也就意味着我们需要VPN的7位()来索引页表。

同时,在上图中我们注意到把高
14位用来索引页目录了,这意味着我们的目录有页,但是一个页目录最多只能只能放128项(我们例子中一个物理页最多只能存放128个页表项),也就是说如果要将16384个页放到一个物理页中的话,每一项都就都保存了128页(),就不是只保存了一个页,因此我们让多级页表每一部分放入一个页的目标失败了。要解决这个问题的话,可以将页目录索引再细分一下,将页目录索引也拆成多个页,如下图所示


- 现在,当索引上层页目录时,我们会取虚拟地址的高7位(图中的pd索引0),用它在一级目录表中获取目录项。
- 如果一级页目录表项的标记有效,则再通过这个PDE的物理帧号和VPN的下一部分(PD索引1)来查阅二级目录。
- 如果标记如果依旧有效,则再加上二级页表的PDE来形成PTE的地址。
这样会增加很多工作量,这些工作只是为了在多级页表中查找某些项。
地址转换过程:记住TLB
为了更深入的理解二级页表的地址转换,我们可以通过代码来更好的理解。
从如下代码中可以看到,在复杂的多级页表访问之前,会先检查TLB,如果TLB未命中,才会做复杂的多级页表访问,下图中也体现了传统两级页表的成本:两次额外的内存访问来查找有效的转换映射
反向页表
还有一种更极端的方式来节省内存空间,叫做反向页表(inverted page table)。这种方式不会给每个进程都开一个页表,而是所有进程都共用一个页表,这个页表的每个项都对应着一个物理页。同时页表项会记录哪个进程在使用这个页,以及进程的哪个虚拟页映射到这个物理页。
在这个页表中,如果要找到正确的项,采用线性扫描的话,开销会很大,因为要完整的遍历一遍这个页表。因此一般会在这个基础结构上建立散列表(hash表)来加速查找,通过VPN和进程号进行hash计算,得到页帧号。PowerPC就是这种架构。
反向页表页证明我们之前一直提过的内容:页表只是数据结构。我们可以让对数据结构做各种改造,让它变大或变小,变快或变慢。多级页表和反向页表就是我们自定义的两个例子
将页表交换到磁盘
我们上述学习了很多方式来减小页表的大小,但是它依旧可能会因为太大而无法加入内存。所以,一些系统将这样的页表放入内核虚拟内存(kernel virtual memory),从而允许操作系统有内存压力时,将这些页表的一部分交换(swap)到磁盘中,有关具体如何交换,我们在下一章进行更详细的学习。