



到目前为止,我们看到了两项关键操作系统技术的发展:CPU的虚拟化是进程;内存的虚拟化是地址空间;在这两种抽象共同作用下,程序运行时就好像它在自己的私有独立世界中一样,好像它有自己的处理器(或多处理器),好像它有自己的内存。这种假象使得对系统编程变得更容易,因此现在不仅在台式机和服务器上盛行,而且在所有可编程平台上越来越普遍,包括手机在内。
在这一章,我们给虚拟化拼图加上最为关键的一块:持久存储(persistent storage)。永久存储设备永久地(或至少长时间地)存储信息,如传统的硬盘驱动器(hard disk drive)或更为现代的固态存储硬盘(solid-state storage drive)。持久存储设备不同于内存。内存在断电时,其内容会丢失,而持久存储设备会保持这些数据不变。因此,操作系统必须特别小心这样的设备:用户用它们保存真正关心的数据。
关键问题:如何管理持久存储设备
操作系统应该如何管理持久存储设备?都需要哪些API?实现有哪些重要方面?
接下里几篇会讨论管理持久数据的一些关键技术,重点是如何提高性能及可靠性。但是,我们先从总体上看看API:你在与UNIX文件系统交互时会看到的接口。
文件和目录
随着时间的推移,存储虚拟化形成了两个关键的抽象。
第一个是文件(file)。文件就是一个线性字节数组,每个字节都可以读取或写入。每个文件都有一个高级名称/可读名称(high-level name),通常是由路径名组成的,如“/home/user/documents/file.txt”。它也有低级名称(low-level name),通常是某种数字。用户不需要关心这个名字。由于历史原因,文件的低级名称通常称为inode号(inode number)。我们将在以后的篇幅学习更多关于inode的内容。现在,只需要知道每个文件都有一个与其关联的inode号。
inode是index node(索引节点)的简写
在大多数系统中,文件系统不太了解文件的结构(例如,它是图片、文本文件还是C代码)。文件系统的责任仅仅是将这些数据永久存储在磁盘上,并确保当你再次请求数据时,得到你原来放在那里的内容。做到这一点并不简单。当你需要访问这些文件时,只需要提供文件名或路径,文件系统就会找到相应的文件并返回给你。
第二个抽象是目录(directory)。目录是一种特殊类型的文件,它包含其它文件和目录的列表。目录可以看作是一个文件系统的“索引”,它使用户能够轻松的找到它们需要的文件。目录也有一个高级名称(high-level name),例如“/home/user/documents”。它也有低级名称,也是inode号,这个inode号记录了目录的元数据信息,例如目录的权限、所有者、创建时间等等。
目录的内容中是一个对的目录(有点类似与一个列表,数组),这里面每一项条目都是一个文件的高级民称到低级名称的映射,把它当成一个简单列表来看:
[(“foo”, “10”), (“bar”, “11”), ("docs", "12")],这是几个文件的高级名称到低级名称的映射。目录中的每个条目都指向文件或其它目录。通过将目录放在其它目录中,用户可以构建任意的目录树(directory tree,或目录层次结构,directory hierarchy),在该目录下存储所有的文件和目录。目录层次结构从根目录(root directory)开始(在基于UNIX的系统中,根目录就记为“/”),并使用某种分隔符(separator)来命名后续子目录(sub-directories),直到命名所需的文件或目录。
例如,如果用户在根目录创建了一个目录 foo,然后在目录foo中创建了一个文件bar.txt,我们就可以通过它的绝对路径名(absolute pathname)来引用该文件,在这个例子中,它将是/foo/bar.txt。更复杂的目录树,请参见右图。示例中的有效目录是/foo,/bar,/bar/bar,/bar/foo,有效的文件是/foo/bar.txt和/bar/foo/bar.txt。目录和文件可以具有相同的名称,只要它们位于文件系统树的不同位置(例如,图中有两个名为bar.txt的文件:/foo/bar.txt和/bar/foo/bbar.txt)

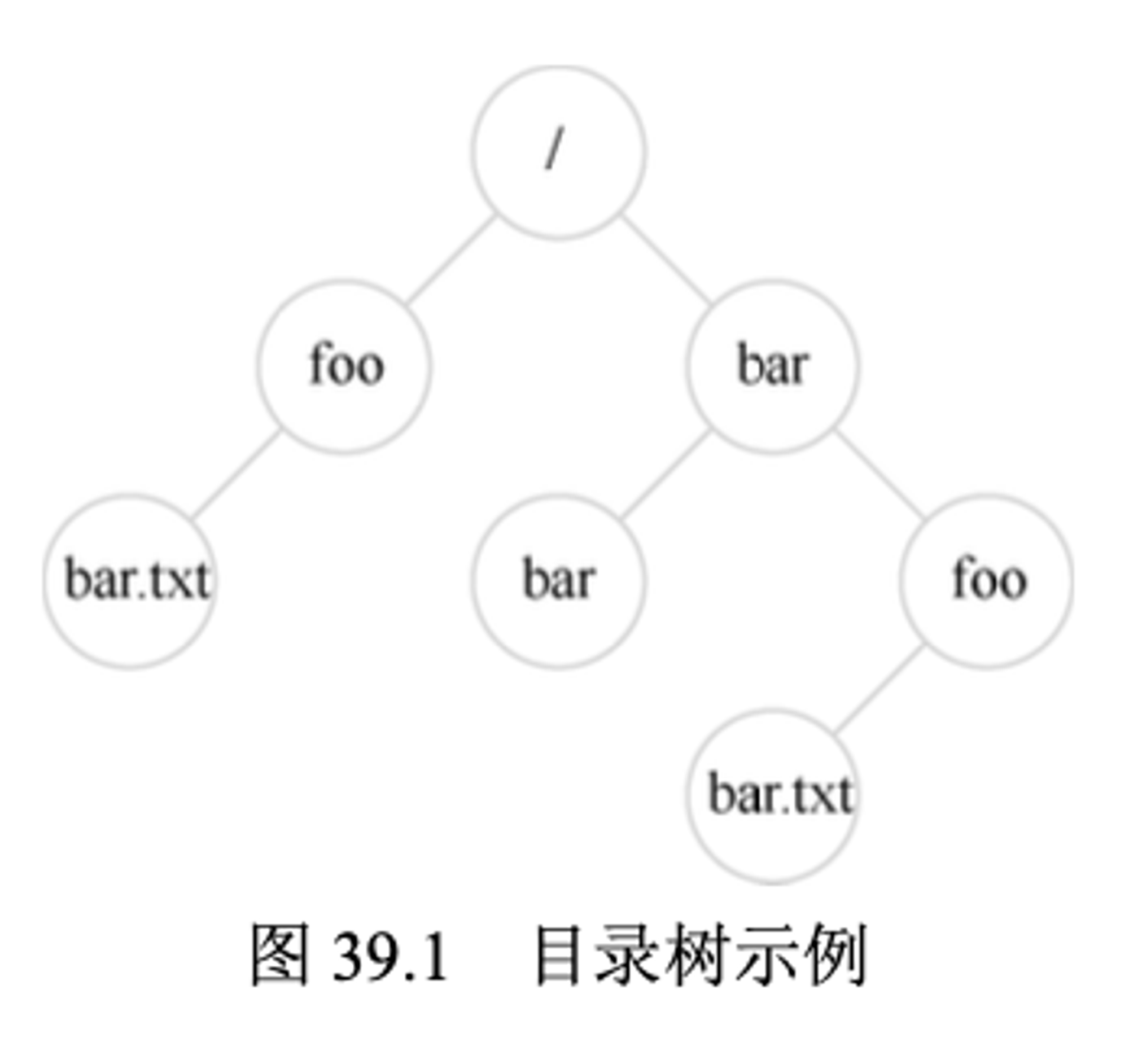
你可能还会注意到,这个例子中的文件名通常包含两部分:bar和txt,以句点分隔。第一部分是任意名称,而文件名的第二部分通常用于指示文件的类型(type),例如,它是C代码(例如.c)还是图像(例如.jpg),或音乐文件(例如.mp3)。然而,这通常只是一个惯例(convention):一般不会强制名为main.c的文件中包含的数据确实是C源代码。
因此,我们可以看到文件系统提供的了不起的东西:一种方便的方式来命名我们感兴趣的所有文件。名称在系统中很重要,因为访问任何资源的第一步是能够命名它。在UNIX系统中,文件系统提供了一种统一的方式来访问磁盘、U盘、CD-ROM、许多其他设备上的文件,事实上还有很多其他的东西,都位于单一目录树下。
文件系统接口
现在让我们更详细地讨论文件系统接口。我们将从创建、访问和删除文件的基础开始。你可能会认为这很简单,但是这个过程中,你会发现用于删除文件的神秘调用,称为unlink()。学习完本章后,将不在对其感到困惑。
创建文件
我们将从最基本的操作开始:创建一个文件。这可以通过open系统调用完成。通过调用open()并传入0_CREAT标志,程序可以创建一个新文件。下面是示例代码,用于在当前工作目录创建名为“foo”的文件。
函数open()接受一些不同的标志。
O_CREAT:如果文件不存在,则创建它。如果文件已经存在,则忽略这个标志。O_WRONLY:以只写模式打开文件。这意味着你只能向文件中写入数据,不能从文件中读取数据。O_TRUNC:如果文件已经存在,则将其截断为0字节。这意味着在打开文件时,文件中的所有数据都将被删除。open()的一个重要方面是它的返回值:文件描述符(file descriptor)。文件描述符只是一个整数,是每个进程私有的,在UNIX系统中用于访问文件。因此,一旦文件被打开,你就可以使用文件描述符来读取或写入文件,假定你有权这样做。这样,一个文件描述符就是一种权限(capability),即一个不透明的句柄,它可以让你执行某些操作。另一种看待文件描述符的方法,是将它作为指向文件类型对象的指针。一旦你有这样的对象,就可以调用其它“方法”来访问文件,如read()和write()。下面你会看到如何使用文件描述符。
“句柄”是计算机科学中的一个术语,通常用于表示对某个资源的引用或指针。在操作系统中,句柄通常用于表示对文件、进程、线程、窗口等资源的引用。句柄是一种抽象的概念,它可以是一个整数、一个指针或其他类型的标识符,具体取决于操作系统和编程语言的实现。
创建完文件之后,我们可以使用
stat foo查看创建的文件信息,如下:请关注其中的links: 1 它是一个引用计数,这表示当前只有位置引用这个inode 1318555,相当于只有一个可读名称”链接“了这个inode。后续我们会理解为什么需要这个计数。补充:creat系统调用
创建文件的旧方法是调用creat,如下所示
int fd = creat ("foo");
你可以认为creat()是open()加上以下标志:O_CREAT|O_WRONLY|O,TRUNC。因为open()可以创建一个文件, 所以creat()的用法有些失宠(实际上, 它可能就是是实现为对open()的一个库调用)。然而, 它确实在UNIX知识中占有一席之地。特别是,有人曾问KenThompson, 如果他重新设计UNIX, 做法会有什么不同,他回答说: "我拼写creat时会加上e"。读写文件
一旦我们有了一些文件,当然就会想要读取或写入。我们先读取一个现有的文件。如果在命令行输入,我们就可以用cat程序,将文件的内容显示到屏幕上
在这段代码中,我们将程序 echo 的输出重定向到文件 foo,然后文件中就包含单词 “hello”。然后我们用 cat 来查看文件的内容。但是,cat 程序如何访问到文件 foo?
为了弄清楚这个问题,我们将使用一个非常有用的工具,来跟踪程序所做的系统调用。 在 Linux 上,该工具称为
strace。其他系统也有类似的工具(参见 macOS X 上的 dtruss,或某些较早的 UNIX 变体上的 truss)。strace 的作用就是跟踪程序在运行时所做的每个系统调用,然后将跟踪结果显示在屏幕上供你查看。提示:使用 strace(和类似工具)
strace 工具提供了一种非常棒的方式,来查看程序在做什么。通过运行它,你可以跟踪程序生成的系统调用,查看参数和返回代码,通常可以很好地了解正在发生的事情。
该工具还接受一些非常有用的参数。例如,-f 跟踪所有 fork 的子进程,-t 报告每次调用的时间,-e trace=open,close,read,write 只跟踪对这些系统调用的调用,并忽略所有其他调用。还有许多更强大的标志,请阅读手册页,弄清楚如何利用这个奇妙的工具。
下面是一个例子,使用 strace 来找出 cat 在做什么(为了可读性删除了一些调用)。
cat 做的第一件事是打开文件准备读取。我们应该注意几件事情。首先,该文件仅为读取而打开(不写入),如 O_RDONLY 标志所示。其次,使用 64 位偏移量(O_LARGEFILE)。 最后,open()调用成功并返回一个文件描述符,其值为 3。
为什么这里是 open("foo", O_RDONLY) ,而不是open("foo", O_RDONLY | O_LARGEFILE)O_LARGEFILE是一个标志位,用于告诉系统打开的文件可能会超过 2GB,需要使用 64 位的文件偏移量。在现代的 Linux 系统中,这个标志位已经默认开启了,因此在打开文件时不需要显式地指定O_LARGEFILE标志位。所以,即使你没有显式地指定O_LARGEFILE标志位,系统也会默认使用 64 位的文件偏移量。因此,在这个例子中,使用 open("foo", O_RDONLY) 就足够了,不需要显式地指定O_LARGEFILE标志位。
你可能会想,为什么第一次调用 open()会返回 3,而不是 0 或 1 ?事实证明,每个正在运行的进程已经打开了 3 个文件: 标准输入(进程可以读取以接收输入),标准输出(进程可以写入以便将信息显示到屏幕),以及标准错误(进程可以写入错误消息)。这些分别由文件描述符 0、1 和 2 表示。因此,当你第一次打开另一个文件时(如上例所示),它几乎肯定是文件描述符 3。
打开成功后,cat使用read()系统调用重复读取文件中的一些字节。read()的第一个参数是文件描述符,从而告诉文件系统读取哪个文件。一个进程当然可以同时打开多个文件,因此描述符使操作系统能够知道某个特定的读取引用了哪个文件。第二个参数指向一个用于放置read()结果的缓冲区。在上面的系统调用跟踪中1,strace显示了这时的读取结果("hello")。第三个参数是缓冲区的大小,在这个例子中是65536。对
read()的调用也成功返回,这里返回它读取的字节数(6,其中包括"hello"中的5个字母和一个行尾标记)。在不同机器上,可能read的第三个参数会不同,书上的示例代码是4096。它的值并不是固定的,而是由操作系统内核根据实际情况动态分配的。
此时,你会看到strace的另一个有趣结果:对write()系统调用的的一次调用,针对文件描述符1。如上所述,此描述符被称为标准输出,因此用于将单词"Hello"写到屏幕上,这正是cat程序要做的事。但是它直接调用write()吗? 也许(如果它是高度优化的)。但是,如果不是,那么可能会调用库例程printf()。在内部,printf()会计算出传递给它的所有格式化细节,并最终对标准输出调用write,将结果显示到屏幕上。
然后,cat程序试图从文件中读取更多内容(
read(3, “”, 65536) ),但由于文件中没有剩余字节,read()返回0,程序知道这意味着它已经读取了整个文件。因此,程序调用close(),传入相应的文件描述符,表明它已用完文件"foo"。该文件因此被关闭,对它的读取完成了。
写入文件是通过一组类似的步骤完成的。首先,打开一个文件准备写入,然后调用write()系统调用,对于较大的文件,可能重复调用,然后调用close()。使用strace追踪写入文件,也许针对你自己编写的程序,或者追踪dd实用程序,例如 dd if = foo of = bar读取或写入,但不按顺序
到目前为止,我们已经讨论了如何读取和写入文件,但所有访问都是顺序的(sequential)。也就是说,我们从头到尾读取一个文件,或者从头到尾写入一个文件。
但是,有时能够读取或写入文件中的特定偏移量是有用的。例如,如果你在文本文件上构建了索引并利用它来查找特定单词,最终可能会从文件中的某些随机(random)偏移中读取数据。为此,我们将使用lseek()系统调用。下面是函数原型:
其中,
fildes 是文件描述符,offset 是偏移量,whence 是起始位置。whence 参数可以取以下三个值之一:- SEEK_SET:从参数offset开始计算偏移量。
- SEEK_CUR:从当前位置开始计算偏移量。
- SEEK_END:从文件末尾开始计算偏移量。
lseek() 系统调用返回设置后的文件偏移量,如果出现错误,则返回 -1,并设置 errno 变量来指示错误类型。从上面的描述中可见,对于每个进程打开的文件,操作系统都会跟踪一个"当前"偏移量,这将决定在文件中读取或写入时,下一次读取或写入开始的位置。因此,打开文件的抽象包括它具有当前偏移量,偏移量的更新有两种方式。第一种是当发生N个字节的读或写时,N被添加到当前偏移。因此,每次读取或写入都会隐式更新偏移量。第二种是明确的lseek,它改变了上面指定的偏移量(使用lessk可以改变文件的偏移量)。例如,如果要从文件开头处读取第 100 个字节(一般会使用某种数据结构来加速定位到索引的位置,如 B-树 或 哈希表),可以使用以下代码:
请注意,调用lseek()与移动磁盘臂的磁盘的寻道(seek)操作无关。对Iseek()的调用只是改变内核中变量的值。执行I/0时,根据磁盘头的位置,磁盘可可能会也可能不会执行实际的寻道来完成请求。
什么是强制写入
大多数情况,当程序调用write()时,它只是告诉文件系统,请在将来的某个时刻,将次数据写入到磁盘中。出于性能的原因,文件系统会将这些写入在内存中缓冲(buffer)一段时间(例如5s或30s)。在之后的某个时间点,才会将实际的写入发送到存储设备。从调用程序的角度来看,写入似乎很快就完成了,并且,只有在极少数情况下数据才会丢失(如,在write()调用之后但写入磁盘之前,机器崩溃)。
显然,有些程序需要的是更安全的保证。例如,在数据库管理系统(DBMS)中,开发正确的恢复协议要求能够经常强制写入磁盘。
为了支持这些类型的应用程序,大多数文件系统都会提供一些额外的控制API。在UNIX中,提供给应用程序接口被称为
fsync(int fd)。当进程针对特定描述符调用fsync()时,文件系统通过强制将所有脏(dirty)数据(即尚未写入的)写入磁盘来响应,针对指定文件描述符引用的文件。一旦所有这些写入完成,fsync()例程就会返回。以下是一个使用fsync()的简单示例。代码打开文件foo,向它写入一个数据块,然后调用fsync()以确保立即强制写入磁盘。一旦fasync()返回,应用程序就可以安全地继续前进,直到数据已被保存
有趣的是,这段代码并不能保证你所期望的一切。在某些情况下,还需要fsync(包含foo文件的目录。添加此步骤不仅可以确保文件本身位于磁盘上,而且可以确保文件(如果新创建)也是目录的一部分。毫不奇怪,这种细节往往被忽略,导致许多应用程序级别的错误[P+13]。
在某些情况下,即使调用了 fsync(),也不能保证数据已经被写入磁盘。这是因为文件系统通常会将文件和目录的元数据(如文件大小、修改时间等)存储在目录中,而不是直接存储在文件中。如果只调用了 fsync(),只能保证文件的数据被写入磁盘,而目录的元数据可能还在内存中,没有被写入磁盘。
文件重命名
有了一个文件后,有时需要给一个文件不同的名字。在命令行键入时,这是通过mv命令完成的。在下面的例子中,文件foo被重命名为bar。
如果我们继续使用strace来追踪,可以看到mv使用了系统调用
rename(char* old, char * new),它只需要两个参数:文件的原来名称和新名称。rename()调用提供了一个有趣的保证:它是一个原子调用,不论操作系统是否崩溃。它只会有成功或者失败的状态,不会出现奇怪的中间状态。对于一些需要对文件进行原子更新的应用程序,rename()非常重要。
在一些旧的操作系统或者旧的版本中,可能使用的是 rename() 系统调用(书上的代码就是),而在一些新的操作系统或者新的版本中,可能使用的是 renameat2() 系统调用。不同的系统调用可能有不同的参数和行为,但它们的作用都是将一个文件重命名为另一个文件。 对于 renameat2(),它的代码示例应该是这样的renameat2(AT_FDCWD, "foo", AT_FDCWD, "bar", 0),其中AT_FD_CWD是文件所在的目录,最后一个参数是标志参数0(即如果目标文件已经存在,则会被覆盖)。 标志参数也有其它值,如 AT_RENAME_NOREPLACE 表示不覆盖已经存在的目标文件,AT_RENAME_EXCHANGE 表示交换源文件和目标文件的内容等。在这个例子中,标志参数为 0,表示使用默认的重命名行为,即如果目标文件已经存在,则会被覆盖。
让我们更具体一点。想象一下,你正在使用文件编辑器(例如lemacs),并将一行插入到文件的中间。例如,该文件的名称是foo.txt。编辑器更新文件并确保新文件包含原有内容和插入行的方式如下(为简单起见,忽略错误检查):
在这个例子中,编辑器做的事很简单:将文件的新版本写入临时名称(foot.txt.tmp),使用fsync()将其强制写入磁盘。然后,当应用程序确定新文件的元数据和内容在磁盘上,就将临时文件重命名为原有文件的名称。最后一步自动离新文件交换到位,同时删除旧版本的文件,从而实现原子文件更新。
获取文件信息
除了文件访问之外,我们还希望文件系统能够保存关于他正在存储的每个文件的大量信息。我们通常将这些数据称为文件元数据(metadata)。要查看特定文件的元数据,我们可以使用stat()或fstat()系统调用。这些调用将一个路径名(或文件描述符)添加到一个文件中,并填充一个stat结构,如下所示:
你可以看到关于每个文件的大量信息,包括其大小(以字节为单位),其低级名称(即inode号),一些所有权信息以及有关何时文件被访问或修改的一些信息,等等。要查看此信息,可以使用命令行工具stat:
事实表明,每个文件系统通常将这种类型的信息存在一个名为inode的结构中。当我们讨论文件系统的实现时,惠学习更多关于inode的只是。就目前而言,你应该将inode看作是有文件系统保存的持久数据结构,包含上述信息。
删除文件
现在,我们知道了如何创建文件并按顺序访问它们。但是,如何删除文件?如果用UNIX,你可能认为你知道:只需运行程序rm。但是,rm使用了什么系统调用来删除文件?我们继续使用strace来查看:
我们从跟踪出删除了一些不相关的内容,只留下一个神秘的系统调用
unlink()。如你所见,unlink()只需要待删除文件的名称,如果删除成功,返回值为 0,否则返回 -1,并设置 errno 错误码。可能你会感到疑惑,为什么这个系统调用叫做unlink(),而不是叫做”remove“或”delete“?如果你能够和之前创建文件时的内容联系起来,估计也能理解的七七八八 (在接下来学习硬链接的时候会详细学习)。unlink() 只能删除文件,不能删除目录。如果要删除目录,需要使用 rmdir() 系统调用。
rm 命令最终会调用 unlink() 系统调用来删除文件。unlink() 系统调用会删除指定的文件,并释放该文件占用的磁盘空间。如果该文件有硬链接,只有当所有硬链接都被删除后,该文件的磁盘空间才会被释放。
小心强大的命令
程序m为我们提供了强大命令的一个好例子,也说明有时太多的权利可能是一件坏事。例如,要一次删除一堆文件,可以键入如下内容:
其中*将匹配当前目录中的所有文件。但有时你也想删除目录,实际上包括它们的所有内容。你可以告诉m以递归方式进入每个目录并删除其内容,从而完成此操作:
如果你发出命令时碰巧是在文件系统的根目录,从而删除了所有文件和目录,这一小串宇符会给你带来麻烦。哎呀!
因此,要记住强大的命令是双刃剑。虽然它们让你能够通过少量击键来完成大量工作,但也可能迅速而容易地造成巨大的伤害。
创建目录
除了文件外,还可以使用一组与目录相关的系统调用来创建、读取和删除目录。请注意,你永远不能直接写入目录(如修改目录文件的某个字节或某个块的内容)。因为目录的格式被视为文件系统元数据,所以你只能间接更新目录。例如,通过在其中创建文件、目录或其他对象类型。通过这种方式、文件系统可以确保目录的内容始终符合预期。
如果要创建目录,可以用系统调用mkdir()。同名的mkdir应用程序可以用来创建一个目录。我们来试一下:
这个目录创建时,它被认为是”空的“,尽管它实际上包含最少得内容。具体来说,空目录有两个条目:一个引用自身的条目,一个引用其父目录的条目。前者称为”.“(点)目录,后者称为”..“(点-点)目录。你可以通过向应用程序ls传递一个标志(-a)来查看这些目录
读取目录
既然我们创建了目录,那么自然可能会对这个目录进行读取。实际上,这就是ls程序做的事。让我们像编写ls这样的小工具,看看它是如何做的。
相对于文件来说,目录使用了一组新的调用。如下是一个小程序,它使用了opendir()、readdir() 和 closedir()这3个系统调用来完成工作,你可以看到接口有多简单。我们只需使用一个简单的循环就可以一次读取一个目录条目,并打印目录中每个文件的名称和inode编号。
对于其中的struct dirent数据结构,其中包含了每个目录条目中可用的信息。
由于目录只有少量的信息(基本上,只是将名称映射到inode号,以及少量其它细节),程序可能需要再每个文件上调用stat()以获取每个文件的更多信息,例如其长度或其它详细信息。实际上,这正是ls带有-l标志时所做的事情。你可以尝试一下带和不带-l参数的ls运行strace,看看运行结果。
删除目录
最后,你可以通过调用rmdir()来删除目录(它由相同名称的程序rmdir使用)。然而,与删除文件不同。由于删除目录的操作很危险,因为可以使用单条命令删除大量数据。因此,rmdir()要求该目录在被删除之前是空的(只有”.“和”..“条目)。如果你试图删除一个非空目录,那么对rmdir()的调用就会失败。
硬链接
理解完什么是硬链接,我们就可以解释,为什么删除文件时,要时候unlink了。首先,我们再来学习一个创建文件的新方法,即link()系统调用。在这之前我们都是使用open()系统调用创建的。link系统调用有两个参数:一个旧路径名和一个新路径名。当你用一个新文件名”链接“到旧文件名时,实际上就是创建了一个硬链接。这可以通过命令行程序 ln 来执行这个操作。如下所示
在这里,我们创建了一个文件,其中包含单词”hello“,并称之为file。然后,我没用ln程序创建了该文件的硬链接。在这之后,我们可以通过打开file或file2来检查文件。
现在file和file2都指向了同一个文件,通过打印文件的inode号可以看到这一点:
我们通过对ls程序加上-i参数,它打印了每个文件的inode编号。因此,你可以看到实际上已完成的链接:只是对同一个inode号创建了新的引用。
现在,我们再来理一下,当创建一个文件时(使用open创建),实际上做了两件事。首先,构建一个结构(inode),它将跟踪几乎所有关于文件的信息,包括其大小、文件块在磁盘上的位置等等。其次,将人类的可读名称链接到该文件,并将该链接放入到目录中,然后会将inode的引用计数加1。
对于硬链接创建的文件,在文件系统中,原有文件名和新创建的文件名之间没有任何区别。实际上,他们都是指向文件底层元数据的链接,可以在inode编号1318557中找到。
对于删除硬链接的文件,我们使用
unlink()(是的,和删除普通文件一样)。如下:这个结果是因为当文件系统取消链接文件时,它检查inode号中的引用计数(reference count)。该引用计数(有时称为链接计数,link count)会跟踪有多少不同的文件名已连接到这个inode。调用unlink()时,会删除人类可读的名称与给定inode号之间的”链接“,并减少引用计数。只有当引用计数达到零时,文件系统才会释放inode和相关数据块,从而真正”删除“该文件。
我们可以用刚刚学会的stat()来查看文件的引用计数。让我们看看创建和删除文件的硬链接时,引用计数的变化(注意其中的 Links: )。在这个例子中,我们为一个文件创建了一个硬链接,然后删除它。
需要注意的是,硬链接只能创建文件的硬链接,不能创建目录的硬链接。
硬链接有点类似于共享航班,即可以通过多加航空公司购买机票,实际上是同一辆飞机。
软连接(符号链接)
还有一种很常用的链接类型,国内习惯称为软链接(soft link),也叫符号链接(symbolic link)。事实证明,硬链接有些局限,刚刚我们也提到了,它不能创建目录的硬链接(因为有可能在目录中会出现环)。你也无法硬链接到其它磁盘分区中的文件(因为inode号在特定文件系统中是唯一的,而不是跨文件系统),等等。因此,人们创建了一种称为符号链接的新型链接,它可以链接目录,这很有用。
要创建这样的链接,可以使用相同的程序ln,但需要加上-s参数。如下是一个例子。
如你所见,到目前为止,软连接和硬链接看起来几乎没什么不太一样,现在可以通过文件名称foo和软链接名称foo2来访问原始文件。
但是,除了我们目前看到的这些,软连接其实和硬链接大不相同。第一个区别就是软链接本身实际上是一个不同类型的文件。我们已经讨论过一常规的文件和目录。软连接不属于我们刚刚探讨的范围内,它属于第三种类型。如果你通过stat来查看,可以看出区别。
通过ls也可以看出差异,仔细观察ls长格式的第一个字符,可以看到常规文件最左列的第一个字符是“-”,目录是“d”,软链接是“l”。你还可以看到软链接的大小(这个例子是3,最后一行,这取决于路径长度)以及链接指向的内容(名为file的文件)
这里我们看到foo2是4个字节。是的,尽管软链接它只是类似一个快捷方式,但是它依旧需要占用一些空间。原因在于形成形成软链接的方式,即将链接指向文件的路径名作为软链接的数据。在这个例子中我们链接到了一个名为foo的文件,所以我的链接文件foo2很小(4个字节)。如果链接到更长的路径名,链接文件会更大。可以看到上面的copytest的链接文件,它的大小就更大。
最后,由于创建软链接的方式,有可能造成所谓的悬空引用(dangling reference),即软链接的目标文件不存在了。
我们也看到了,软链接和硬链接的不同。对于这个例子来说,如果是硬链接的话,当执行cat foo2的时候是不会报错的,但是软链接的话,目标文件被删除了,那么这个快捷方式也就失效了。
到这里时,我突然想到jyy老师举得一个例子:“在用u盘拷贝电脑上文件的时候,把桌面的所有图标都选中,然后复制到u盘中,以为这样就把所有的软件都复制了,结果打开的时候发现全是失效的快捷方式😂”
创建并挂载文件系统
我们现在已经了解了文件、目录和特定类型链接(硬、软链接)的基本接口。但是我们还应该讨论另一个话题:如何从许多底层文件系统组建完整的目录树。这项任务的实现需要先制作一个文件系统,然后把这个文件系统挂载到操作系统个一些预设目录下,这样才能使得这些文件能够访问。
为什么需要先制造文件系统?
让我们来举个例子。假设你有一张空白的纸,你想在上面画一幅画。那么你需要先准备好画笔、颜料等工具,然后开始画画。这个过程就相当于创建一个文件系统,你需要准备好文件系统的类型、大小等参数,然后使用一个工具(比如mkfs)来创建这个文件系统。
但是,你画完了这幅画,它只是存在于这张纸上,如果你想要展示给别人看,或者将它放在画廊里展览,你就需要将这张纸挂在墙上或者放在画框里。这个过程就相当于挂载文件系统,你需要选择一个目录作为挂载点,然后将这个文件系统挂载到这个目录下,这样你就可以在这个目录下访问这个文件系统中的文件和目录了。
为了创建一个文件系统,大多数文件系统提供了一个工具,即mkfs(发音为 “makefs”),他就是完成这个任务的,对于这个工具来说,它只需要指定两个参数,输入设备或者文件系统。如:
输入设备如何该如何查看? 可以用lsblk命令来列出系统中的所有块设备(包括硬盘、U 盘等等),以及它们的分区情况。这个命令会输出一个树形结构,让你很容易地看到每个设备和分区的名称、大小、挂载状态等等信息。外,你也可以使用fdisk命令来查看磁盘分区的信息。这个命令可以列出磁盘上的所有分区,以及它们的起始位置、大小、文件系统类型等等信息。你可以使用fdisk -l命令来列出所有的分区信息。当你知道了输入设备的名称之后,你就可以使用 mkfs 命令来创建文件系统了。
当我们创建完文件系统之后,我们就可以将它挂载到一个目录下了,我们可以使用mount命令来将这个文件系统挂载,它需要指定两个参数,输入设备和挂载点,输入设备就是你想要挂载的文件系统所在的设备,比如
/dev/sda1。挂载点则是你想要将文件系统挂载到哪个目录下,比如 /home/users。我们可以使用如下命令将我们刚刚创建好的文件系统挂载到/home/usersmount的挂载点我该如何设置? 在文件系统还没有挂载的时候,这个目录(如home/users)是如何出现的呀,这个目录是系统中自带的吗? 在 Linux 系统中,有一个特殊的目录叫做根目录(root directory),它是整个文件系统的起点,所有的文件和目录都是从根目录开始的。在根目录下,通常会有一些预设的目录,比如 /bin、/etc、/home、/usr 等等,这些目录都是系统中自带的,它们的作用和用途也都有所不同。
假设我们的输入设备中已经包含了个两个子目录a和b,每个子目录一次包含一个名为foo的文件。当我们挂载成功之后,我们使用ls命令来查看一下:
如你所见,路径名/home/users/现在是值得新挂载目录的根。同样,我们可以使用路径名/home/users/a和/home/users/b访问到目录a和b。最后,可以通过/home/users/a/foo和 /home/users/b/foo访问名为foo的两个文件。因此mount的美妙之处在于:它将所有的文件系统统一到一棵树中,而不是用用多个独立的文件系统,这让命名同意而且方便。
如果要查看系统上挂载的内容,以及在哪些位置挂载,只要运行mount程序。就可以看到类似下面的内容: